Computing with Text: Counting words#
Turning Text into Vectors#
In many different Data Science projects or tasks, we often find ourselves needing to transform our data into a format that is more suitable for computation and analysis. When dealing with textual data, this means converting our words into numeric representations, often in the form of vectors. But why vectors, you may ask? Machine Learning algorithms, at their core, work with numerical data. They’re able to identify patterns, trends, and relationships within numeric data much more effectively. Numerical vectors are a very suitable input for machine learning models. In addition, such vectors allow direct use of methods from algebra, for instance to compute distances or similarities between data points.
Distance/similarity measures#
Depending on the type of numerical vector, there are many suitable methods to compute vector-vector similarities (or inverse: distances). For real-numbered (float) vectors, we can for instance simply use the Euclidean distance, which you will know from Pythagoras. Often a better choice for larger vectors is the Cosine similarity based on the angle between two vectors. For binary vectors, there are other measures such as the Jaccard similarity.
One-Hot Encoding#
The first step towards this transformation is to use a method known as One-Hot Encoding. In this process, each word in the sentence is represented as a vector in an N-dimensional space where N is the number of unique words in the sentence. Each word is represented as a vector of length N, with all elements being 0, except for one element which is 1, indicating the presence of the word.
For instance, consider the sentences: “I like cats” and “I like dogs”. In a one-hot encoding scheme, these sentences would be represented by the vectors:
I: [1, 0, 0, 0]
like: [0, 1, 0, 0]
cats: [0, 0, 1, 0]
dogs: [0, 0, 0, 1]
With this encoding, we can calculate the Euclidean distance between these sentence vectors, providing a way to compare sentences. However, this method has limitations. The vectors can become extremely large for sentences with many unique words, and all words are treated as orthogonal, meaning the distance between any two different words is always the same, which is often not what we want.
For instance, consider the sentences:
“That is the one and only way to happiness.”
and
“That is the one and only way to die.”
Despite having only one word difference, the Euclidean distance between these sentences would be very small since only one word differs. The distance between “happiness” and “die” is the same as between “That” and “This”, even though the first has a much larger impact on the meaning of the sentence.
import os
import requests
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb
from sklearn.feature_extraction.text import TfidfVectorizer
# Set the ggplot style
plt.style.use("ggplot")
# That is the one and only way to happiness
vector1 = np.array([1, 1, 1, 1, 1, 1, 1, 1, 1, 0])
# That is the one and only way to die
vector2 = np.array([1, 1, 1, 1, 1, 1, 1, 1, 0, 1])
# This is the one and only way to happiness
vector3 = np.array([0, 1, 1, 1, 1, 1, 1, 1, 1, 1])
distance = np.sqrt(np.sum(vector1 ** 2 + vector2 ** 2))
print(f"Distance between vector1 and vector2: {distance:.3f}.")
distance = np.sqrt(np.sum(vector1 ** 2 + vector3 ** 2))
print(f"Distance between vector1 and vector3: {distance:.3f}.")
Distance between vector1 and vector2: 4.243.
Distance between vector1 and vector3: 4.243.
Term Frequency-Inverse Document Frequency (TF-IDF)#
To resolve these issues, we use a more sophisticated method called Term Frequency-Inverse Document Frequency (TF-IDF). This measure helps us to evaluate how important a word is to a document within a corpus. The importance increases proportionally to the number of times a word appears in the document but is offset by the frequency of the word in the corpus.
The TF-IDF weight is composed of two terms:
The Term Frequency (TF), which is the frequency of a word in a document. It is computed as:
The Inverse Document Frequency (IDF) is computed as the logarithm of the number of documents in the corpus divided by the number of documents where the specific term appears.
The TF-IDF weight is then the product of these two quantities:
How important is a word? A simple TF-IDF example#
Consider the following small corpus:
with two documents:
d1: That is the one and only way to happiness.
d2: That is the one and only way to die.
The term frequency (TF) of a word \(w_i\) in a document \(d\) is defined as:
The inverse document frequency (IDF) of a word \(w_i\) in a corpus \(D\) is defined as:
The TF-IDF score combines both quantities:
For document \(d_1\), both that and happiness occur once in a document with nine words:
The word die does not occur in \(d_1\):
The word that occurs in both documents, so its IDF is zero:
The word die occurs only in one document:
For document \(d_2\), this gives:
This illustrates the main idea of TF-IDF: words that occur in many documents, such as that, receive a low weight, while words that are more specific to a document, such as die, receive a higher weight.
This results in a vector space model where each word is assigned a TF-IDF score, and a document is represented as a vector of these scores. We can use libraries like Scikit-Learn[Pedregosa et al., 2011] to compute these scores easily.
Finally, we can use these TF-IDF vectors to train Machine Learning models. For example, we can train a logistic regression model (see Common Algorithms II - Linear Models) for sentiment analysis.
In this chapter, and the next one, we will see that turning words into vectors is a fundamental approach in NLP that opens up countless new possibilities for analysis and model training.
Hands-on: Hotel Reviews#
Let’s work with some actual data!
We here will work with a dataset of about 20,000 hotel reviews from TripAdvisor (see original dataset on zenodo or see dataset on kaggle). The goal will be to train a machine learning model to predict hotel ratings based on a review text.
Data import and exploration#
As in the previous chapters, we import the data using Pandas. We will then explore the data a bit. However, since this dataset was already prepared to work for machine learning tasks in this case, there are no complicated data processing steps that we have to do at this point.
File downloaded successfully and saved to ../datasets/tripadvisor_hotel_reviews.csv
filename = "../datasets/tripadvisor_hotel_reviews.csv"
try:
data = pd.read_csv(filename, encoding="cp1252")
except UnicodeDecodeError:
data = pd.read_csv(filename, encoding="utf-8", encoding_errors="ignore")
data.head()
| S.No. | Review | Rating | |
|---|---|---|---|
| 0 | 1 | nice hotel expensive parking got good deal sta... | 4 |
| 1 | 2 | ok nothing special charge diamond member hilto... | 2 |
| 2 | 3 | nice rooms not 4* experience hotel monaco seat... | 3 |
| 3 | 4 | unique \tgreat stay \twonderful time hotel mon... | 5 |
| 4 | 5 | great stay great stay \twent seahawk game awes... | 5 |
data.info()
<class 'pandas.DataFrame'>
RangeIndex: 20491 entries, 0 to 20490
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 S.No. 20491 non-null int64
1 Review 20491 non-null str
2 Rating 20491 non-null int64
dtypes: int64(2), str(1)
memory usage: 480.4 KB
plt.figure(dpi=300)
sb.countplot(data=data,
x="Rating",
palette="viridis",
hue="Rating",
).set_title("Rating Distribution")
Text(0.5, 1.0, 'Rating Distribution')
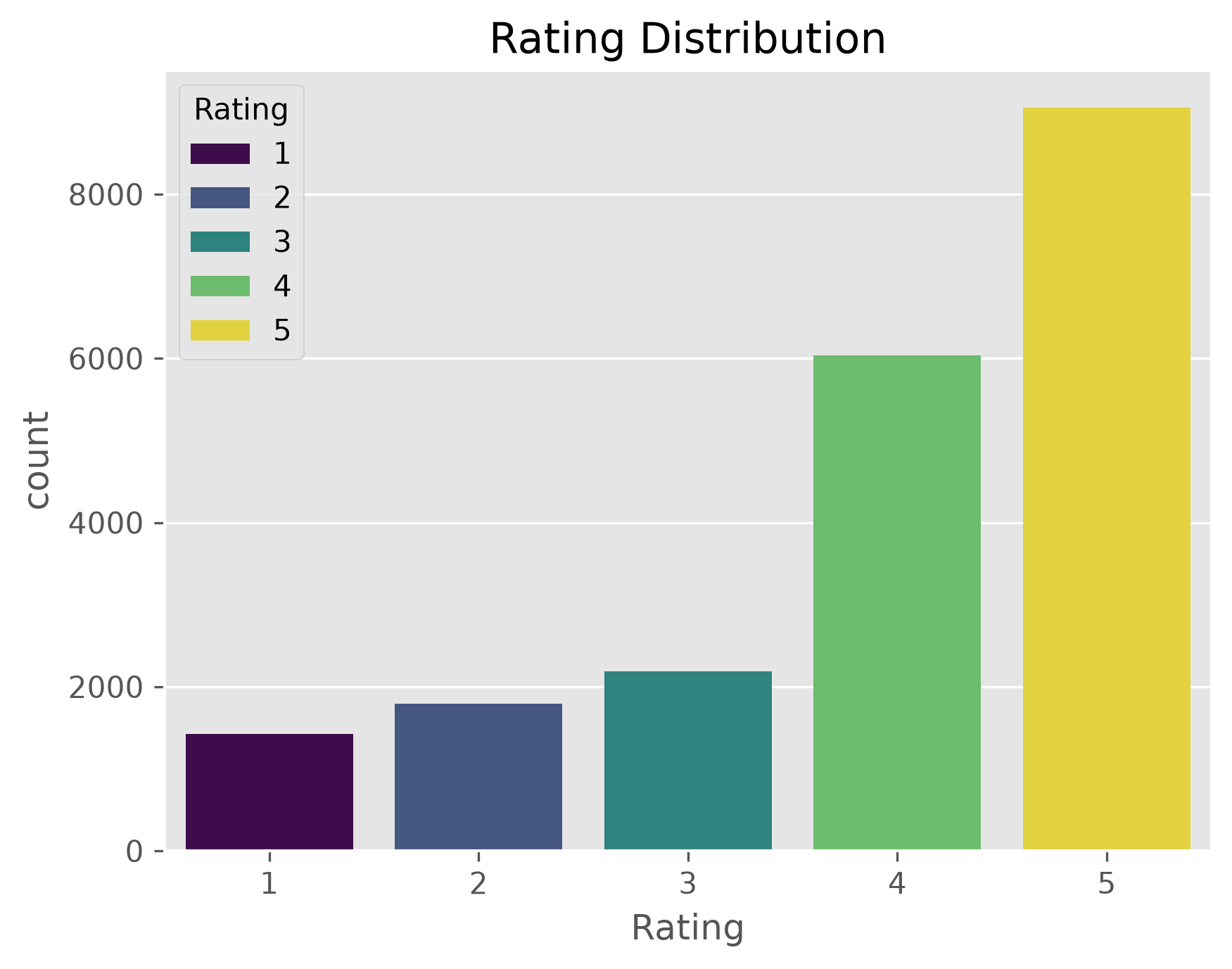
Here we see a first potential issue, a bias of the ratings. The dataset contains far more positive reviews (>= 4) than neutral or negative ones. This is a common problem in machine learning and there are strategies to deal with this (e.g. oversampling or using class weights), but for now we will simply ignore it.
Train/Test Split#
Let us first split the data into a training and test set (see chapters on machine learning!).
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
data['Review'], data['Rating'],
test_size=0.2,
random_state=0
)
print(f"Train dataset size: {X_train.shape}")
print(f"Test dataset size: {X_test.shape}")
Train dataset size: (16392,)
Test dataset size: (4099,)
tfidf = TfidfVectorizer()
tfidf_vectors = tfidf.fit_transform(X_train)
tfidf_vectors.shape
(16392, 46735)
This is a pretty big array (or matrix). So, how does such a tfidf vector look like, for instance the tfidf-vector for the first review?
# This is the review
data.iloc[0, 0]
np.int64(1)
# And this is the tfidf-vector of this review
tfidf_vectors[0, :]
<Compressed Sparse Row sparse matrix of dtype 'float64'
with 247 stored elements and shape (1, 46735)>
What does sparse matrix mean?#
We have seen before, that such sentence (or text) vector can quickly become very long. Here each vector as 47073 positions, one for each word. But most of these words do not occur in a particular sentence, so most positions in a tfidf-vector are simply 0.
To save all those numbers would be very vastefull memory wise. So, scikit-learn here uses so called sparse matrices which only store the data for non-zero positions. We can look at the data with the .data attribute. Or we can convert it to a dense vector (that includes all zeros) by using .toarray().
Reduce tfidf vector size#
So far we simply used the TfidfVectorizer without setting any parameters, which means that it will simply use default values. In our case, however, we end up with rather large tfidf vectors. In particular given the relatively small dataset (small for NLP standards) and the rather short reviews.
In many cases, and here as well, we also deal with text data of strongly varying quality. This can lead to many words in the tfidf model which are not meaningfull enough. We can have a look at the words which were included:
# Have a look at the last 100 words in the tfidf model
tfidf.get_feature_names_out()[-100:]
array(['zambia', 'zambuca', 'zamora', 'zana', 'zandaam', 'zandberg',
'zandbergen', 'zanzadog', 'zanzibar', 'zapata', 'zapatero', 'zapp',
'zappaz', 'zapped', 'zapper', 'zara', 'zaranegatives', 'zarracin',
'zarzuela', 'zawodniaks', 'zaza', 'zazen', 'zea', 'zealand',
'zealous', 'zebra', 'zebrano', 'zeil', 'zekes', 'zell', 'zelma',
'zen', 'zenith', 'zepplin', 'zero', 'zeroom', 'zeroplus', 'zest',
'zhi', 'zia', 'ziggy', 'zigzags', 'zilch', 'zilli', 'zillion',
'zillions', 'zine', 'zinhua', 'zip', 'zipcars', 'zipline',
'ziploc', 'ziplock', 'zipped', 'zippered', 'zipping', 'zishan',
'zissonpalm', 'zito', 'zocalo', 'zocolo', 'zoe', 'zoetrope',
'zofoji', 'zoila', 'zombie', 'zombies', 'zona', 'zone', 'zoned',
'zones', 'zonethis', 'zoning', 'zoo', 'zoogarten', 'zooji',
'zoological', 'zoologicher', 'zoologische', 'zoologischer',
'zoologisher', 'zoom', 'zooming', 'zooms', 'zoomy', 'zoran',
'zorbas', 'zucca', 'zuid', 'zum', 'zumo', 'zurich', 'zvago',
'zyrtec', 'zytec', 'zz', 'zzzt', 'zzzzt', 'zzzzzs', 'zzzzzzzzz'],
dtype=object)
Many of those words make no sense! This includes rare strings and typos.
In such cases, it is generally advisable to reduce the number of words in our TF-IDF vector by removing words that either occur very rarely (only a few times in the entire dataset) or very often (in a large portion of the documents). Words that rarely occur provide little value to our machine learning models because they hardly appear during training. Conversely, words that occur frequently likely have minimal discriminative power because they are so common.
Both issues can be addressed easily with the TfidfVectorizer by setting the min_df (minimum document frequency) and max_df (maximum document frequency) parameters. These can be set using integers or floats. For example, min_df=10 means that a word must appear at least 10 times to be included. On the other hand, max_df=0.25 means that words appearing in more than 25% of all documents are excluded from our TF-IDF vectors.
tfidf = TfidfVectorizer(min_df=10, max_df=0.25)
tfidf_vectors = tfidf.fit_transform(X_train)
tfidf_vectors.shape
(16392, 8530)
# Again have a look at the last 100 words in the tfidf model
tfidf.get_feature_names_out()[-100:]
array(['work', 'worked', 'worker', 'workers', 'working', 'workmen',
'workout', 'works', 'world', 'worlds', 'worldwide', 'worn',
'worried', 'worries', 'worry', 'worrying', 'worse', 'worst',
'worth', 'worthwhile', 'worthy', 'wotif', 'would', 'wouldn____',
'wouldnt', 'wound', 'wow', 'wrap', 'wrapped', 'wraps', 'wreck',
'wrist', 'wristband', 'write', 'writing', 'written', 'wrong',
'wrote', 'wrought', 'wtc', 'www', 'wyndham', 'wynyard', 'xmas',
'ya', 'yahoo', 'yard', 'yards', 'yea', 'yeah', 'year', 'yearly',
'years', 'yell', 'yelled', 'yelling', 'yellow', 'yen', 'yep',
'yes', 'yesterday', 'yet', 'yikes', 'yo', 'yoga', 'yoghurt',
'yoghurts', 'yogurt', 'yogurts', 'york', 'yorker', 'yorkers',
'you', 'you___', 'you___e', 'you___l', 'young', 'younger',
'youngest', 'your', 'youre', 'yourself', 'youth', 'yr', 'yrs',
'yuan', 'yuck', 'yuk', 'yum', 'yummy', 'yunque', 'zealand', 'zen',
'zero', 'zip', 'zocalo', 'zona', 'zone', 'zones', 'zoo'],
dtype=object)
This already looks much better! The data still contains some weird words, but we will leave those for now.
tfidf_vectors[0, :].data
array([0.0539729 , 0.06313062, 0.13342997, 0.14238643, 0.03442771,
0.16475053, 0.05087098, 0.12082107, 0.02682429, 0.07496162,
0.06270785, 0.06856957, 0.05117407, 0.12318464, 0.06431871,
0.03733884, 0.09592062, 0.03639212, 0.03610359, 0.04590719,
0.05928236, 0.03247833, 0.02768546, 0.08459947, 0.07080069,
0.0248119 , 0.04108411, 0.0321014 , 0.03376561, 0.06798908,
0.05102129, 0.03919231, 0.0598716 , 0.04173029, 0.03933486,
0.06217982, 0.04992661, 0.0504341 , 0.04420783, 0.03234872,
0.07496162, 0.04408728, 0.0743204 , 0.09427286, 0.05052943,
0.03258889, 0.13079219, 0.02379212, 0.04886691, 0.0289582 ,
0.06351002, 0.04059439, 0.04008237, 0.02897704, 0.05267547,
0.02630802, 0.03738532, 0.08372265, 0.09976363, 0.03533473,
0.06641361, 0.06027284, 0.03636078, 0.03314756, 0.09757427,
0.06469744, 0.03862969, 0.03610359, 0.03411121, 0.03802404,
0.09464094, 0.06801074, 0.04445372, 0.05936221, 0.14631426,
0.02853526, 0.05809023, 0.04635482, 0.03825135, 0.03294313,
0.05993139, 0.03342479, 0.06453238, 0.06134686, 0.045734 ,
0.07508446, 0.03880442, 0.0726259 , 0.07335499, 0.05273602,
0.05948696, 0.04745715, 0.05052943, 0.05687624, 0.04420783,
0.05439415, 0.03131748, 0.04745715, 0.0323555 , 0.07750061,
0.0458781 , 0.14569402, 0.05461457, 0.03363245, 0.02767726,
0.02935703, 0.07970347, 0.07774502, 0.03232842, 0.03355499,
0.02987181, 0.05454052, 0.06159232, 0.10983369, 0.06013716,
0.04328459, 0.09476442, 0.0503868 , 0.11752477, 0.03830263,
0.04556399, 0.04077712, 0.03033462, 0.04270951, 0.02668698,
0.06351002, 0.03839305, 0.04780791, 0.03775356, 0.04749164,
0.05538952, 0.06699244, 0.10952896, 0.09380731, 0.13442782,
0.0910719 , 0.05275092, 0.23160899, 0.02664655, 0.03150116,
0.13851952, 0.05164809, 0.06520453, 0.04423213, 0.04423213,
0.05249616, 0.06757351, 0.07315713, 0.07614816, 0.09568745,
0.0430246 , 0.0333415 , 0.04491341, 0.04752625, 0.04134791,
0.04091231, 0.04420783, 0.03287836, 0.03906585, 0.04738856,
0.10685891, 0.03707606, 0.06258907, 0.0743204 , 0.06757351,
0.0556352 , 0.04911044, 0.06313062, 0.05538952, 0.06920824,
0.06727843, 0.05349514, 0.06434848, 0.02390612, 0.0627661 ,
0.03518647, 0.03785101, 0.04033485, 0.04425649, 0.30829061,
0.077203 , 0.03243037, 0.03747896, 0.03642358, 0.04915166,
0.04784373, 0.05403801, 0.05605966, 0.05001684, 0.02755109,
0.06618375, 0.05359631, 0.05623502, 0.05736295, 0.04081073,
0.03304478, 0.06885748, 0.02705902, 0.06957276, 0.04150986,
0.03138441, 0.05396839, 0.04136577, 0.04218746, 0.0743204 ,
0.0743204 , 0.03329639, 0.02538626, 0.05588754, 0.07378402,
0.10952896, 0.14152171, 0.07372058, 0.04813533, 0.06699244])
tfidf_vectors[0, :].indices
array([1503, 5974, 8146, 2046, 6006, 2260, 1448, 662, 4547, 2770, 4534,
1211, 5143, 5097, 5296, 7757, 604, 8151, 5137, 5932, 899, 3765,
6551, 5955, 304, 892, 8216, 3863, 6478, 6917, 6113, 7455, 7339,
2554, 8434, 7608, 4811, 4755, 3238, 4833, 4928, 6978, 903, 4396,
8441, 7889, 2892, 855, 2110, 6787, 7140, 3959, 7864, 5282, 255,
963, 2821, 7878, 249, 4298, 3747, 5745, 1670, 1295, 3578, 5198,
8383, 4329, 1242, 1434, 8398, 258, 7962, 6025, 5696, 4411, 3146,
7456, 1453, 8430, 7396, 656, 1904, 2548, 6604, 6286, 4157, 6605,
6287, 6688, 725, 5893, 6344, 2044, 4741, 3916, 5078, 8463, 3676,
5683, 7900, 5682, 3636, 2818, 6267, 4980, 3459, 3748, 8163, 7754,
8042, 8247, 1807, 6826, 3794, 1624, 6485, 7665, 3, 0, 5652,
5075, 2414, 3471, 3171, 8320, 6859, 5624, 4787, 3360, 7548, 847,
5076, 2547, 4809, 5189, 8288, 2385, 8328, 2917, 6817, 6553, 5721,
1040, 1376, 2298, 5407, 8106, 6376, 8364, 3456, 121, 149, 2967,
6767, 473, 2927, 2908, 7300, 1450, 6432, 3877, 4669, 8204, 4620,
3434, 7236, 8207, 3358, 778, 1712, 302, 4967, 6071, 6205, 1333,
4968, 301, 2478, 2977, 3272, 4457, 1479, 5399, 2958, 5070, 336,
5903, 7651, 7255, 2382, 8230, 4023, 7240, 1706, 3624, 8384, 8272,
1555, 5552, 5275, 6621, 7979, 6923, 2269, 2803, 3745, 7836, 4970,
871, 6698, 6612, 991, 864, 2895], dtype=int32)
example_vector = pd.DataFrame({
"word": tfidf.get_feature_names_out()[tfidf_vectors[0, :].indices],
"tfidf": tfidf_vectors[0, :].data
})
example_vector
| word | tfidf | |
|---|---|---|
| 0 | check | 0.053973 |
| 1 | rainforest | 0.063131 |
| 2 | vieques | 0.133430 |
| 3 | culebra | 0.142386 |
| 4 | rate | 0.034428 |
| ... | ... | ... |
| 210 | seven | 0.109529 |
| 211 | seas | 0.141522 |
| 212 | bioluminescent | 0.073721 |
| 213 | bay | 0.048135 |
| 214 | fajardo | 0.066992 |
215 rows × 2 columns
# we don't really want to look at the full vector (let's do 20)
print(tfidf_vectors[0, :].toarray()[0, :20])
print(tfidf_vectors[0, :].toarray().shape)
[0.03830263 0. 0. 0.11752477 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. ]
(1, 8530)
Regression or Classification?#
When we deal with supervised machine learning tasks, those involve labels or targets. Such tasks usually fall under two main categories: Regression and Classification.
As we already discussed in the machine learning part of the course (see Supervised Machine Learning - Introduction), regression generally refers to predicting a continuous number while classification refers to the prediction of specific, discrete values.
If we want to predict if a mail is spam or not, or if we want to predict if an image displays a dog, a cat, or a parrot, we have a classification task.
Here we want to predict ratings between 0 (bad) and 5 (very good), so what kind of task is this? What do you think?
Actually, this case is a bit of a gray zone.
The ratings are discrete numbers: 1, 2, 3, 4, or 5. But the ratings are also ordered, so that predicting a 2 where the true label is a 1 is not that bad! When we train a model on a classification task, then it usually doesn’t matter which wrong class was predicted, so predicting a 2 where it’s actually 1 is as bad as predicting a 4 [1]. So, that makes regression to appear as the natural choice…
However, in practice, training a model on a classification task typically works notably better in such situations where we only have very few possible ordered values (see also [Gupta et al., 2010]).
Nevertheless, we will start with a linear regression model and than compare it to a logistic regression model.
y_train.head()
4115 4
16210 5
4075 4
8215 3
6499 4
Name: Rating, dtype: int64
Linear Regression model#
This model is fast to train an can handle the size of this data fairly well.
It will output floats instead of the actual labels 1 to 5.
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(tfidf_vectors, y_train)
LinearRegression()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
Fitted attributes
Evaluate the model#
For this we will first convert the test data using the exact same tfidf model as for the train data. This is very important, if you compute a new tfidf model using fit or fit_transform, this approach won’t work!
tfidf_vectors_test = tfidf.transform(X_test)
predictions = model.predict(tfidf_vectors_test)
np.round(predictions[:20], 1)
array([1.9, 1.7, 5.6, 6.1, 3.7, 4.7, 3.5, 1.6, 5.1, 3.7, 3.9, 4. , 5.3,
4.5, 4.3, 5.3, 5.7, 3. , 4.5, 4.4])
y_test[:20].values
array([2, 2, 4, 5, 3, 5, 4, 3, 4, 5, 4, 4, 4, 4, 5, 5, 5, 4, 5, 5])
How good are the predictions?
plt.figure(dpi=300)
sb.histplot(predictions - y_test)
plt.show()
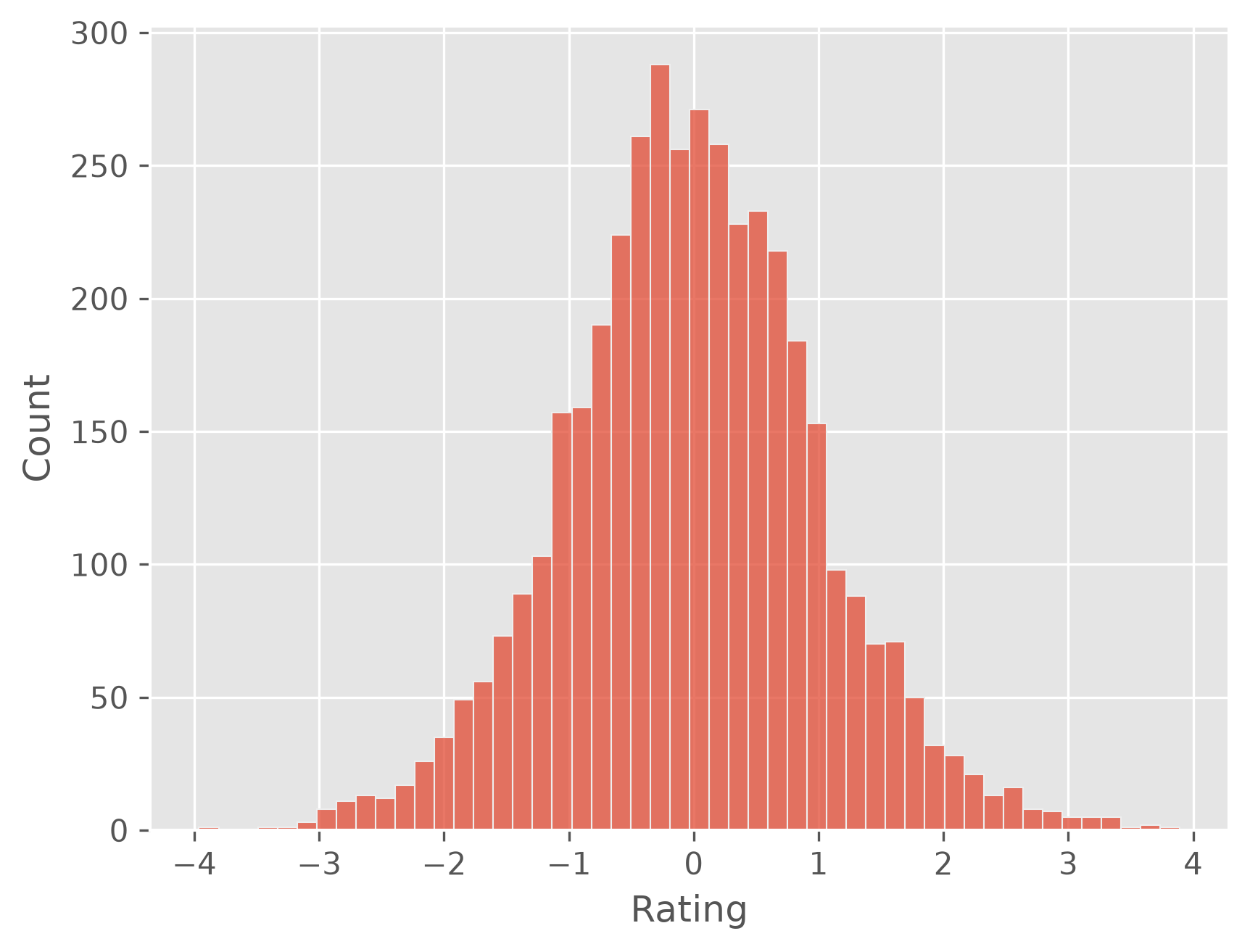
# mean absolute error:
np.abs(predictions - y_test).mean()
np.float64(0.7871552254732878)
A mean absolute error of 0.8 for ratings from 1 to 5 is not a spectacularly good result, but it isn’t bad either. There is one very particular problem due to the linear regression model though:
predictions.min(), predictions.max()
(np.float64(-1.8631768682804744), np.float64(7.25259508754613))
Prediction of impossible values#
The linear regression model has no bounds and could in principle output any float value. Here we got impossible negative values and ratings > 5. This could of course be fixed by simply adding an additional line of code that sets all values < 1 to 1 and all values > 5 to 5.
predictions[predictions < 1] = 1
predictions[predictions > 5] = 5
print(f"Mean absolute error after clipping the predictions: {np.abs(predictions - y_test).mean()}")
Mean absolute error after clipping the predictions: 0.6741914327154894
plt.figure(dpi=300)
sb.histplot(predictions - y_test)
plt.show()
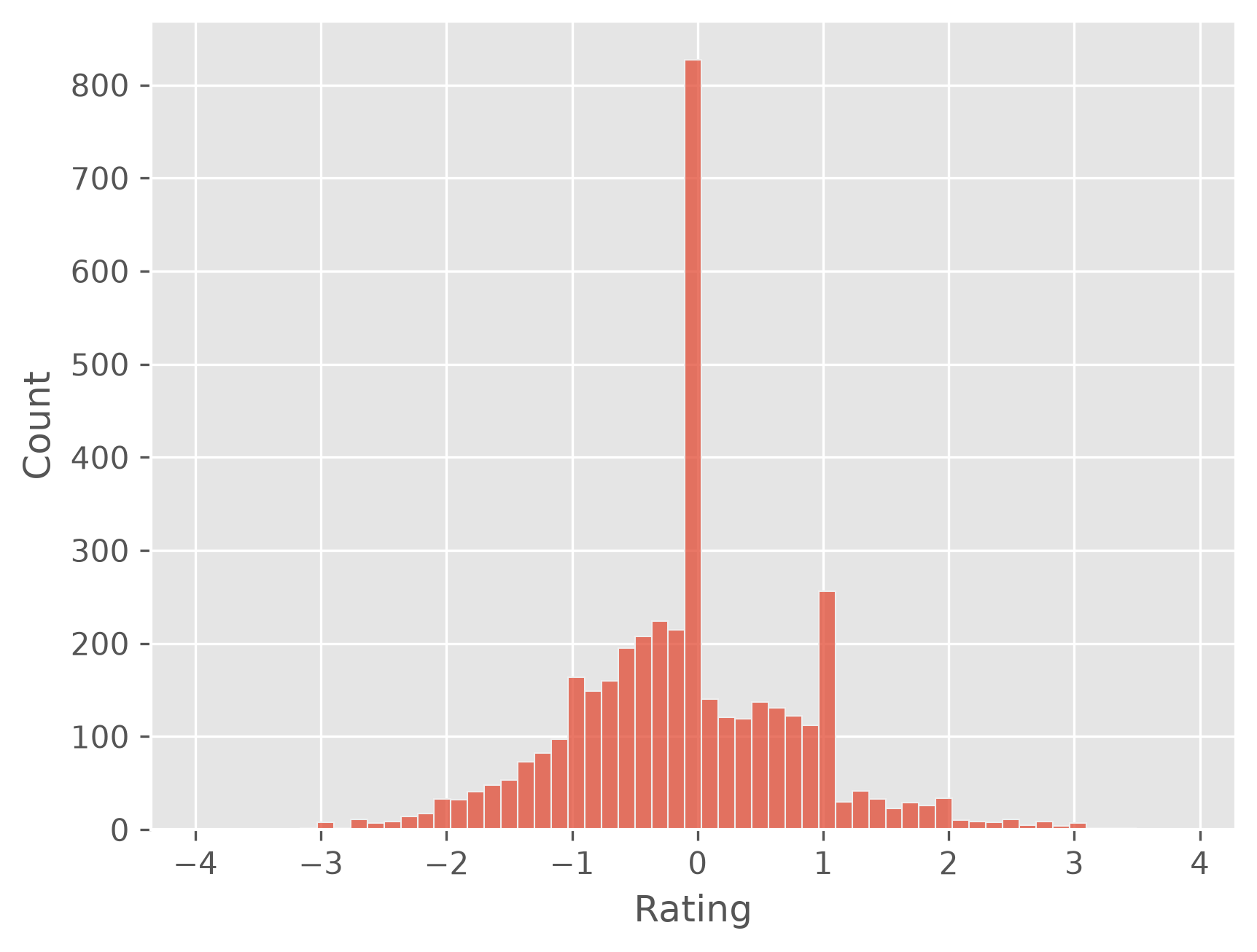
Interestingly, this clipping step improved the quality of the predictions notably which can both be seen in the mean absolute error (MAE) and the error distribution.
Logistic Regression model#
We will now use the logistic regression model. Remember, despite its name this is a model use for classification and not regression.
Hint: In the following coding parts, please don’t worry if you get warnings about reaching the iterations limit. If you want, you can add a higher max_iter value (the Scikit-Learn default value is 100).
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(max_iter=1000)
model.fit(tfidf_vectors, y_train)
LogisticRegression(max_iter=1000)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
Fitted attributes
tfidf_vectors_test = tfidf.transform(X_test)
predictions = model.predict(tfidf_vectors_test)
np.round(predictions[:20], 1)
array([2, 4, 5, 5, 4, 5, 5, 2, 5, 5, 4, 4, 4, 5, 5, 5, 5, 4, 4, 5])
y_test[:20].values
array([2, 2, 4, 5, 3, 5, 4, 3, 4, 5, 4, 4, 4, 4, 5, 5, 5, 4, 5, 5])
plt.figure(dpi=300)
sb.histplot(predictions - y_test)
plt.show()
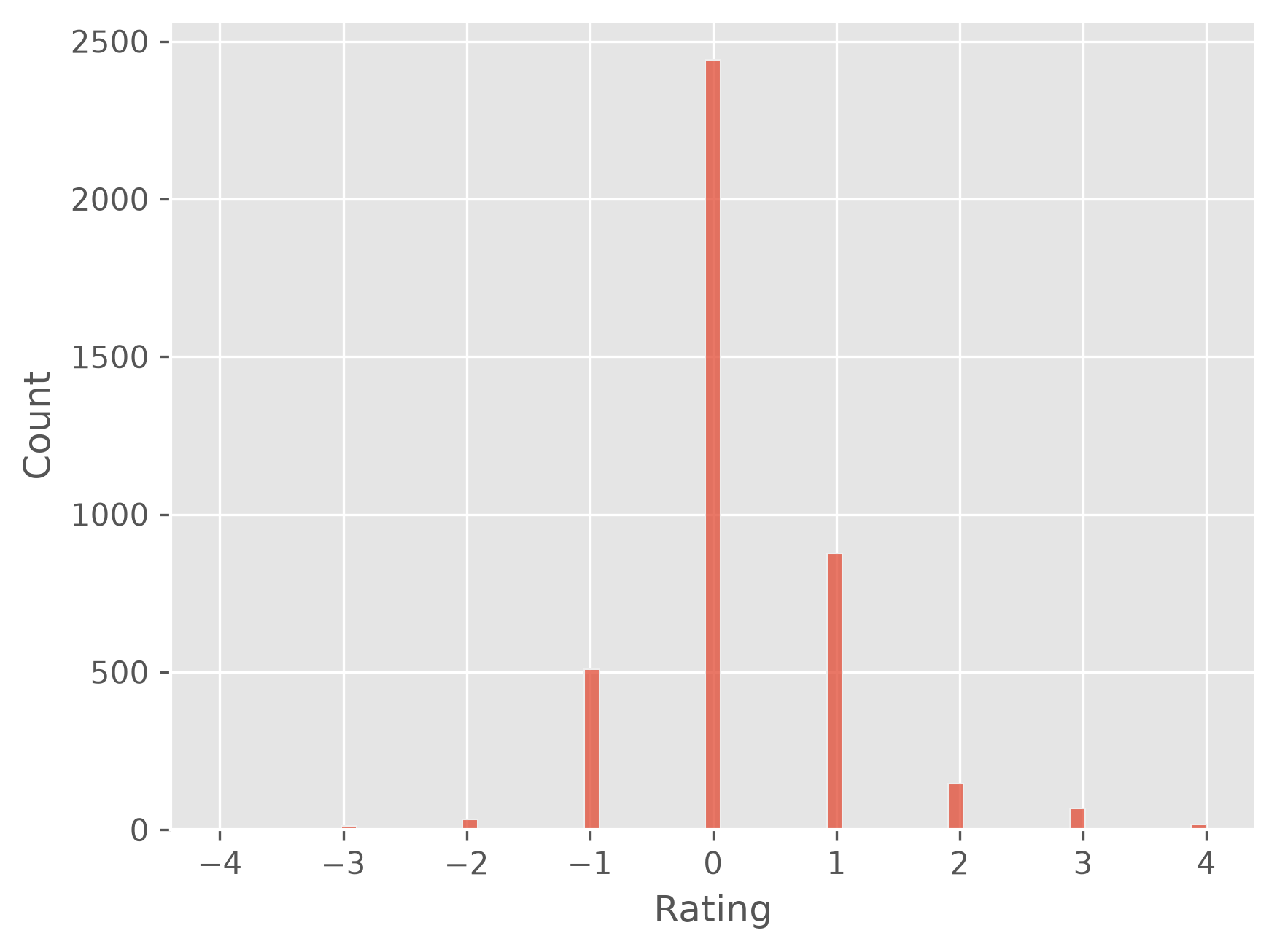
# mean absolute error:
np.abs(predictions - y_test).mean()
np.float64(0.4989021712612832)
Back to: regression vs. classification#
For a classification task it usually does not make sense to compute mean absolute errors. But here it does. And it allows us to compare the performance of the linear regression vs. the logistic regression model. And, as spoiled above, the classification task does indeed result in better predictions!
from sklearn.metrics import confusion_matrix, classification_report
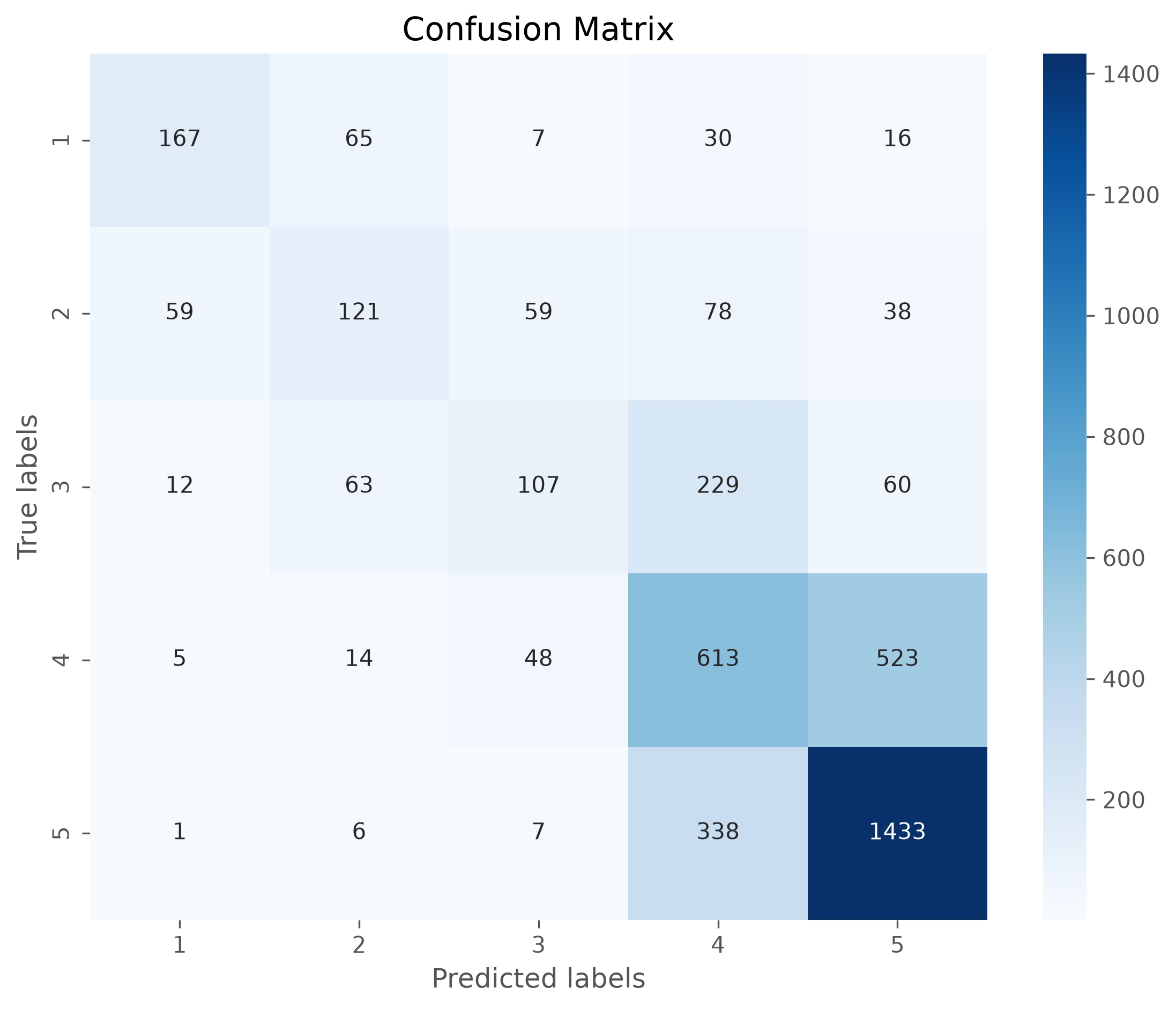
print(confusion_matrix(y_test, predictions))
print(classification_report(y_test, predictions))
[[ 167 65 7 30 16]
[ 59 121 59 78 38]
[ 12 63 107 229 60]
[ 5 14 48 613 523]
[ 1 6 7 338 1433]]
precision recall f1-score support
1 0.68 0.59 0.63 285
2 0.45 0.34 0.39 355
3 0.47 0.23 0.31 471
4 0.48 0.51 0.49 1203
5 0.69 0.80 0.74 1785
accuracy 0.60 4099
macro avg 0.55 0.49 0.51 4099
weighted avg 0.58 0.60 0.58 4099
Confusion matrix#
The confusion matrix can tell us a lot about where the model works well and where it fails. Often is is more accessible if the matrix is plotted, for instance using seaborns heatmap.
cm = confusion_matrix(y_test, predictions, labels=model.classes_)
# Plotting the confusion matrix with a heatmap
plt.figure(figsize=(9,7), dpi=300)
sb.heatmap(cm, annot=True, fmt='d',
cmap='Blues',
xticklabels=model.classes_,
yticklabels=model.classes_)
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.title('Confusion Matrix')
plt.show()
Convert your prediction tasks#
Sometimes it can help to change the actual prediction task to make it clearer, and thereby simpler, for a machine learning model to learn. In the present case we could for instance say that we convert that ratings 1 to 5 into only three categories: bad (1 or 2), neutral (3), or good (4 or 5).
This is of course less nuanced, but it can make it an easier classification task.
# Change the rating to Good - Neutral - Bad
def convert_rating(score):
if score > 3:
return 'good'
if score == 3:
return 'neutral'
return 'bad'
data["rating_simplified"] = data['Rating'].apply(convert_rating)
data.head()
| S.No. | Review | Rating | rating_simplified | |
|---|---|---|---|---|
| 0 | 1 | nice hotel expensive parking got good deal sta... | 4 | good |
| 1 | 2 | ok nothing special charge diamond member hilto... | 2 | bad |
| 2 | 3 | nice rooms not 4* experience hotel monaco seat... | 3 | neutral |
| 3 | 4 | unique \tgreat stay \twonderful time hotel mon... | 5 | good |
| 4 | 5 | great stay great stay \twent seahawk game awes... | 5 | good |
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
data['Review'],
data["rating_simplified"],
test_size=0.2,
random_state=0)
print(f"Train dataset size: {X_train.shape}")
print(f"Test dataset size: {X_test.shape}")
Train dataset size: (16392,)
Test dataset size: (4099,)
tfidf = TfidfVectorizer()
tfidf_vectors = tfidf.fit_transform(X_train)
tfidf_vectors.shape
(16392, 46735)
model = LogisticRegression(max_iter=1000)
model.fit(tfidf_vectors, y_train)
LogisticRegression(max_iter=1000)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
Fitted attributes
tfidf_vectors_test = tfidf.transform(X_test)
predictions = model.predict(tfidf_vectors_test)
predictions[:20]
array(['bad', 'bad', 'good', 'good', 'good', 'good', 'good', 'bad',
'good', 'good', 'good', 'good', 'good', 'good', 'good', 'good',
'good', 'good', 'good', 'good'], dtype=object)
y_test[:20].values
<StringArray>
[ 'bad', 'bad', 'good', 'good', 'neutral', 'good', 'good',
'neutral', 'good', 'good', 'good', 'good', 'good', 'good',
'good', 'good', 'good', 'good', 'good', 'good']
Length: 20, dtype: str
from sklearn.metrics import confusion_matrix, classification_report
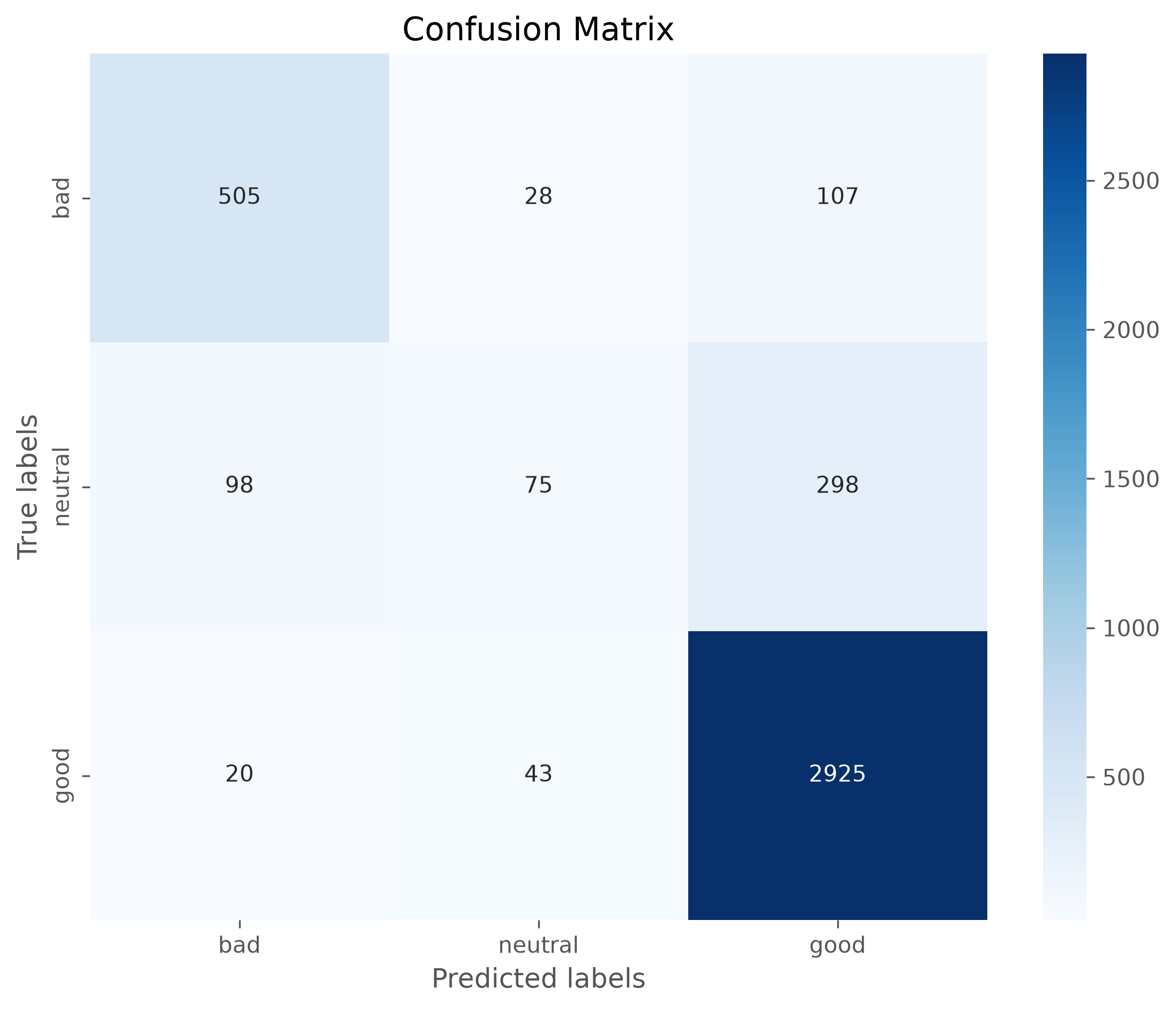
print(confusion_matrix(y_test, predictions))
print(classification_report(y_test, predictions))
[[ 505 107 28]
[ 20 2925 43]
[ 98 298 75]]
precision recall f1-score support
bad 0.81 0.79 0.80 640
good 0.88 0.98 0.93 2988
neutral 0.51 0.16 0.24 471
accuracy 0.86 4099
macro avg 0.73 0.64 0.66 4099
weighted avg 0.83 0.86 0.83 4099
labels = ["bad", "neutral", "good"]
cm = confusion_matrix(y_test, predictions, labels=labels)
# Plotting the confusion matrix with a heatmap
plt.figure(figsize=(9,7), dpi=300)
sb.heatmap(cm, annot=True, fmt='d',
cmap='Blues',
xticklabels=labels,
yticklabels=labels)
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.title('Confusion Matrix')
plt.show()
Question to you:#
Judge yourself. Is this a good result? Could this be done better (and if so, how?) ?