21. Beyond Counting Individual Words: N-grams#
So far in our journey through text data processing, we’ve dealt with counting individual words. While this approach, often referred to as a “bag of words” model, can provide a basic level of understanding and can be useful for certain tasks, it often falls short in capturing the true complexity and richness of language. This is mainly because it treats each word independently and ignores the context and order of words, which are fundamental to human language comprehension.
For example, consider the two phrases
“The movie is good, but the actor was bad.”
and
“The movie is bad, but the actor was good.”
If we simply count individual words, both phrases are identical because they contain the exact same words! However, their meanings are diametrically opposed. The order of words and the context in which they are used are important.
21.1. N-grams#
N-grams are continuous sequences of n items in a given sample of text or speech. In the context of text analysis, an item can be a character, a syllable, or a word, although words are the most commonly used items. The integer n in “n-gram” refers to the number of items in the sequence, so a bigram (or 2-gram) is a sequence of two words, a trigram (3-gram) is a sequence of three words, and so on.
To illustrate, consider the two sentences above. With 3-grams we could also get the pieces “movie is good”, “movie is bad”, “actor was bad”, and “actor was good”. Bigrams (or 2-grams) would not catch those differences. But they can also be very helpful in cases such as “don’t like” vs “do like”.
Now we will see how we can make use of such n-grams.
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb
from sklearn.feature_extraction.text import TfidfVectorizer
21.2. N-grams in TF-IDF Vectors#
When creating TF-IDF vectors, we can incorporate the concept of n-grams. The scikit-learn TfidfVectorizer provides the ngram_range parameter that allows us to specify the range of n-grams to include in the feature vectors.
21.2.1. Dataset - Madrid Restaurant Reviews#
We will now use a large, text-based dataset containing more than 176.000 restaurant reviews from Madrid (see dataset on zenodo). The dataset (about 142MB) can be downloaded via the following code block.
Show code cell source
"""
This code block downloads the data from zenodo and stores it in a local 'datasets' folder.
"""
import requests
import os
def download_from_zenodo(url, save_path):
"""
Downloads a file from a given Zenodo link and saves it to the specified path.
Parameters:
- url: The Zenodo link to the file to be downloaded.
- save_path: Path where the file should be saved.
"""
# Check if the file already exists
if os.path.exists(save_path):
print(f"File {save_path} already exists. Skipping download.")
return None
response = requests.get(url, stream=True)
response.raise_for_status()
with open(save_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
print(f"File downloaded successfully and saved to {save_path}")
# Zenodo link to the dataset
zenodo_link = r"https://zenodo.org/records/6583422/files/Madrid_reviews.csv?download=1"
# Path to save the downloaded dataset (you can modify this as needed)
output_path = os.path.join("..", "datasets", "madrid_reviews.csv")
# Create directory if it doesn't exist
os.makedirs(os.path.dirname(output_path), exist_ok=True)
# Download the dataset
download_from_zenodo(zenodo_link, output_path)
File downloaded successfully and saved to ../datasets/madrid_reviews.csv
filename = "../datasets/madrid_reviews.csv"
data = pd.read_csv(filename)
data = data.drop(["Unnamed: 0"], axis=1)
data.head()
| parse_count | restaurant_name | rating_review | sample | review_id | title_review | review_preview | review_full | date | city | url_restaurant | author_id | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | Sushi_Yakuza | 4 | Positive | review_731778139 | Good sushi option | The menu of Yakuza is a bit of a lottery, some... | The menu of Yakuza is a bit of a lottery, some... | December 10, 2019 | Madrid | https://www.tripadvisor.com/Restaurant_Review-... | UID_0 |
| 1 | 11 | Azotea_Forus_Barcelo | 1 | Negative | review_766657436 | Light up your table at night | Check your bill when you cancel just in case y... | Check your bill when you cancel just in case y... | August 23, 2020 | Madrid | https://www.tripadvisor.com/Restaurant_Review-... | UID_1 |
| 2 | 12 | Level_Veggie_Bistro | 5 | Positive | review_749493592 | Delicious | I had the yuca profiteroles and the veggie bur... | I had the yuca profiteroles and the veggie bur... | March 6, 2020 | Madrid | https://www.tripadvisor.com/Restaurant_Review-... | UID_2 |
| 3 | 13 | Sto_Globo_Sushi_Room | 5 | Positive | review_772422246 | Loved this place | A friend recommended this place as one of the ... | A friend recommended this place as one of the ... | September 29, 2020 | Madrid | https://www.tripadvisor.com/Restaurant_Review-... | UID_3 |
| 4 | 14 | Azotea_Forus_Barcelo | 5 | Positive | review_761855600 | Amazing terrace in madrid | Amazing terrace in madrid - great atmosphere a... | Amazing terrace in madrid - great atmosphere a... | July 27, 2020 | Madrid | https://www.tripadvisor.com/Restaurant_Review-... | UID_4 |
data.shape
(176848, 12)
data.review_full[2]
'I had the yuca profiteroles and the veggie burger, by recommendation of the server. It was absolutely delicious and the service was outstanding. I will definitely be back again with friends !'
from sklearn.feature_extraction.text import TfidfVectorizer
# considers both unigrams and bigrams
vectorizer = TfidfVectorizer(ngram_range=(1, 2))
tfidf_vectors = vectorizer.fit_transform(data.review_full)
tfidf_vectors.shape
(176848, 1496963)
This way, we are not just considering the frequency of individual words, but also the frequency of sequences of words, which often capture more meaning than the individual words alone.
But: this creates even bigger tfidf vectors!
Now we end up with vectors of about 1 million entries (even though most will be zero most of the time).
21.3. TF-IDF with Bigrams: Growing Vectors and Managing High Dimensionality#
The power of n-grams comes at a cost. Specifically, as we increase the size of our n-grams, the dimensionality of our feature vectors also increases. In the case of bigrams, for every pair of words that occur together in our text corpus, we add a new dimension to our feature space. This can quickly lead to an explosion of features. For instance, a modest vocabulary of 1,000 words leads to a potential of 1,000,000 (1,000 x 1,000) bigrams.
This high dimensionality can lead to two issues:
Sparsity: Most documents in the corpus will not contain most of the possible bigrams, leading to a feature matrix where most values are zero, i.e., a sparse matrix.
Computational resources: The computational requirement for storing and processing these feature vectors can become significant, especially for large text corpora.
Several techniques can help manage this high-dimensionality problem:
Feature selection: We can limit the number of bigrams we include in our feature vector. This could be done based on the frequency of the bigrams. For example, we could choose to include only those bigrams that occur more than a certain number of times in the corpus.
Dimensionality reduction: Techniques such as Principal Component Analysis (PCA) or Truncated Singular Value Decomposition (TruncatedSVD) can be used to reduce the dimensionality of the feature space, while preserving as much of the variance in the data as possible.
Using Hashing Vectorizer: Scikit-learn provides a
HashingVectorizerthat uses a hash function to map the features to indices in the feature vector. This approach has a constant memory footprint and does not require to keep a vocabulary dictionary in memory, which makes it suitable for large text corpora.
It’s important to weigh the trade-offs between capturing more context using n-grams and managing the resulting high dimensionality.
Let us here use the simplest way to reduce the tfidf vector size: a more restrictive feature selection!
vectorizer = TfidfVectorizer(min_df=10, max_df=0.2,
ngram_range=(1, 2))
tfidf_vectors = vectorizer.fit_transform(data.review_full)
tfidf_vectors.shape
(176848, 119341)
This looks much better! Maybe we can even include 3-grams?
vectorizer = TfidfVectorizer(min_df=5, max_df=0.25,
ngram_range=(1, 3))
tfidf_vectors = vectorizer.fit_transform(data.review_full)
tfidf_vectors.shape
(176848, 481562)
This looks OK, at least size-wise. The reason why this doesn’t explode in terms of vector size is that the min_df parameter also counts for 2-grams, 3-grams etc. This here means that only the 3-grams which occur at least min_df-times will be kept.
Now we should check which ngrams the tfidf model finally included.
vectorizer.get_feature_names_out()[-100:]
array(['zone of the', 'zone so', 'zones', 'zoo', 'zoo and', 'zoomed',
'zucca', 'zucchini', 'zucchini and', 'zucchini carpaccio',
'zucchini flowers', 'zucchini ravioli', 'zucchini salad',
'zucchini salad and', 'zucchini soup', 'zucchini which',
'zucchini with', 'zuchini', 'zuma', 'zumo', 'zumo de',
'zumo de naranja', 'zurbano', 'ángel', 'área', 'ástor', 'ático',
'él', 'époque', 'ñeru', 'ôven', 'último', 'único', 'über', 'очень',
'אוכל', 'מאוד', 'מומלץ', 'جدا', '가격도', '같아요', '같이', '굉장히', '그리고',
'너무', '다른', '다시', '덕분에', '마드리드', '마드리드에', '마드리드에서', '많이', '맛있게',
'맛있고', '맛있습니다', '맛있어요', '맛있었습니다', '맛있었어요', '매우', '먹고', '먹었는데',
'먹었습니다', '먹을', '메뉴', '모두', '바로', '보다', '빠에야', '상그리아', '스페인',
'시켰는데', '식당', '여기', '여행', '원래', '음식', '음식도', '음식이', '입맛에', '있는',
'있어서', '저희', '정말', '조금', '좋아요', '좋았어요', '좋은', '직원들도', '직원분이', '진짜',
'추천', '추천합니다', '친절하게', '친절하고', '친절합니다', '특히', '한국인', '한국인 입맛에',
'함께', '해서'], dtype=object)
vectorizer.get_feature_names_out()[-1]
'해서'
Well, that does not always immediately look like very good word combinations. We do see a lot of 2-grams and 3-grams. Most combinations of 2 or 3 words, however, seem to be grammatically wrong.
Why is that?
The reason is that our selection criteria (using min_df and max_df) removed a lot of very common words so that yes it does becomes yes does.
But we can leave it to the machine learning algorithms now to make more sense of it.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
data.review_full, data.rating_review, test_size=0.2, random_state=0)
print(f"Train dataset size: {X_train.shape}")
print(f"Test dataset size: {X_test.shape}")
Train dataset size: (141478,)
Test dataset size: (35370,)
vectorizer = TfidfVectorizer(min_df=10, max_df=0.2,
max_features=10000,
#ngram_range=(1, 2)
)
tfidf_vectors = vectorizer.fit_transform(X_train)
tfidf_vectors.shape
(141478, 10000)
vectorizer.get_feature_names_out()[-100:]
array(['worried', 'worries', 'worry', 'worse', 'worst', 'worth', 'worths',
'worthwhile', 'worthy', 'woth', 'would', 'wouldn', 'wouldnt',
'wound', 'wow', 'wowed', 'wrap', 'wrapped', 'wrapping', 'wraps',
'write', 'writer', 'writers', 'writing', 'written', 'wrong',
'wrongly', 'wrote', 'wrought', 'wth', 'www', 'x2', 'ximenez',
'xmas', 'xo', 'xx', 'ya', 'yaki', 'yakisoba', 'yakitori',
'yakitoro', 'yam', 'yamil', 'yang', 'yards', 'yeah', 'year',
'years', 'yell', 'yelled', 'yelling', 'yellow', 'yelp', 'yep',
'yerbabuena', 'yes', 'yesterday', 'yet', 'yo', 'yoghurt', 'yogurt',
'yolk', 'york', 'young', 'younger', 'youngest', 'youngsters',
'your', 'youre', 'yours', 'yourself', 'yourselves', 'youthful',
'youtube', 'yr', 'yrs', 'yuca', 'yucca', 'yuck', 'yum', 'yumm',
'yummie', 'yummy', 'yuzu', 'zalacain', 'zamburinas', 'zamburiñas',
'zara', 'zen', 'zenith', 'zerain', 'zero', 'zone', 'zones', 'zoo',
'zucchini', 'zumo', '너무', '맛있었어요', '정말'], dtype=object)
This time we will start right away with a classification model:
21.3.1. Logistic Regression model#
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(max_iter=300) # don't worry it also works without setting max_iter
model.fit(tfidf_vectors, y_train)
LogisticRegression(max_iter=300)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
LogisticRegression(max_iter=300)
tfidf_vectors_test = vectorizer.transform(X_test)
predictions = model.predict(tfidf_vectors_test)
np.round(predictions[:20], 1)
array([4, 5, 4, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 3, 5, 4, 5, 5])
y_test[:20].values
array([5, 5, 4, 5, 3, 5, 5, 5, 5, 4, 5, 5, 4, 5, 5, 3, 5, 5, 5, 5])
sb.histplot(predictions - y_test)
plt.xlabel("prediction error")
Text(0.5, 0, 'prediction error')

# mean absolute error:
np.abs(predictions - y_test).mean()
0.3780039581566299
from sklearn.metrics import confusion_matrix, classification_report
cm = confusion_matrix(y_test, predictions, labels=model.classes_)
# Plotting the confusion matrix with a heatmap
plt.figure(figsize=(9,7))
sb.heatmap(cm, annot=True, fmt='d',
cmap='Blues',
xticklabels=model.classes_,
yticklabels=model.classes_,
vmax=5000
)
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.title('Confusion Matrix')
plt.show()

vectorizer = TfidfVectorizer(min_df=10, max_df=0.2,
max_features=10000,
ngram_range=(1, 3))
tfidf_vectors = vectorizer.fit_transform(X_train)
tfidf_vectors.shape
---------------------------------------------------------------------------
KeyboardInterrupt Traceback (most recent call last)
Cell In[21], line 4
1 vectorizer = TfidfVectorizer(min_df=10, max_df=0.2,
2 max_features=10000,
3 ngram_range=(1, 3))
----> 4 tfidf_vectors = vectorizer.fit_transform(X_train)
5 tfidf_vectors.shape
File ~/micromamba/envs/data_science/lib/python3.10/site-packages/sklearn/feature_extraction/text.py:2138, in TfidfVectorizer.fit_transform(self, raw_documents, y)
2131 self._check_params()
2132 self._tfidf = TfidfTransformer(
2133 norm=self.norm,
2134 use_idf=self.use_idf,
2135 smooth_idf=self.smooth_idf,
2136 sublinear_tf=self.sublinear_tf,
2137 )
-> 2138 X = super().fit_transform(raw_documents)
2139 self._tfidf.fit(X)
2140 # X is already a transformed view of raw_documents so
2141 # we set copy to False
File ~/micromamba/envs/data_science/lib/python3.10/site-packages/sklearn/base.py:1474, in _fit_context.<locals>.decorator.<locals>.wrapper(estimator, *args, **kwargs)
1467 estimator._validate_params()
1469 with config_context(
1470 skip_parameter_validation=(
1471 prefer_skip_nested_validation or global_skip_validation
1472 )
1473 ):
-> 1474 return fit_method(estimator, *args, **kwargs)
File ~/micromamba/envs/data_science/lib/python3.10/site-packages/sklearn/feature_extraction/text.py:1401, in CountVectorizer.fit_transform(self, raw_documents, y)
1399 raise ValueError("max_df corresponds to < documents than min_df")
1400 if max_features is not None:
-> 1401 X = self._sort_features(X, vocabulary)
1402 X, self.stop_words_ = self._limit_features(
1403 X, vocabulary, max_doc_count, min_doc_count, max_features
1404 )
1405 if max_features is None:
File ~/micromamba/envs/data_science/lib/python3.10/site-packages/sklearn/feature_extraction/text.py:1213, in CountVectorizer._sort_features(self, X, vocabulary)
1211 for new_val, (term, old_val) in enumerate(sorted_features):
1212 vocabulary[term] = new_val
-> 1213 map_index[old_val] = new_val
1215 X.indices = map_index.take(X.indices, mode="clip")
1216 return X
KeyboardInterrupt:
vectorizer.get_feature_names_out()[-100:]
array(['you are not', 'you ask', 'you ask for', 'you can', 'you can also',
'you can buy', 'you can choose', 'you can eat', 'you can enjoy',
'you can find', 'you can get', 'you can go', 'you can have',
'you can order', 'you can see', 'you can sit', 'you can try',
'you cannot', 'you choose', 'you come', 'you could', 'you do',
'you do not', 'you don', 'you don want', 'you eat', 'you enjoy',
'you enter', 'you expect', 'you feel', 'you feel like', 'you find',
'you for', 'you get', 'you get the', 'you go', 'you go to',
'you have', 'you have the', 'you have to', 'you in', 'you just',
'you know', 'you like', 'you ll', 'you ll be', 'you ll find',
'you love', 'you make', 'you may', 'you might', 'you must',
'you must try', 'you need', 'you need to', 'you order', 'you pay',
'you pay for', 'you re', 'you re in', 'you re looking',
'you re not', 'you really', 'you see', 'you should', 'you sit',
'you the', 'you to', 'you try', 'you ve', 'you visit', 'you walk',
'you want', 'you want to', 'you were', 'you will', 'you will be',
'you will find', 'you will have', 'you will not', 'you with',
'you won', 'you won be', 'you won regret', 'you would',
'you would expect', 'young', 'your', 'your food', 'your meal',
'your money', 'your mouth', 'your own', 'your place', 'your table',
'your time', 'your way', 'yourself', 'yum', 'yummy'], dtype=object)
21.3.1.1. Question!#
Why did we now get a notably smaller tfidf vector length?
tfidf_vectors[0, :].data
array([0.1387891 , 0.13512541, 0.14732539, 0.11708958, 0.14946676,
0.11511072, 0.1444836 , 0.13665878, 0.14979188, 0.10268665,
0.08515603, 0.12004832, 0.10720641, 0.11965181, 0.12394399,
0.092254 , 0.14979188, 0.11356895, 0.10914472, 0.14331753,
0.09882652, 0.10212461, 0.09038474, 0.09779526, 0.09394805,
0.14525597, 0.12540266, 0.13598151, 0.12847323, 0.14875365,
0.11584212, 0.11375017, 0.11152386, 0.12644517, 0.1377188 ,
0.07982853, 0.05498834, 0.13392387, 0.11242216, 0.14367861,
0.1499564 , 0.14313935, 0.1202977 , 0.07495173, 0.14612707,
0.11327957, 0.13124683, 0.056673 , 0.05969443, 0.1270542 ,
0.08700208, 0.14599061, 0.07204574, 0.1137082 , 0.08188261,
0.10429517, 0.08306113, 0.07947322, 0.07596308, 0.12319629,
0.09291383, 0.09143116, 0.10948931, 0.178938 , 0.12462447,
0.09796248, 0.10013418, 0.11864844, 0.11132398, 0.08634848,
0.09937276, 0.09949771, 0.08454477, 0.05570801, 0.09212747])
tfidf_vectors[0, :].indices
array([8292, 3801, 7590, 9155, 9260, 4170, 9254, 3032, 4240, 9844, 6542,
6429, 8291, 7868, 6832, 3800, 9342, 3792, 2735, 4848, 7587, 5121,
2055, 9154, 1465, 938, 6612, 9259, 3320, 1125, 5068, 9866, 704,
8424, 7817, 9058, 4141, 6406, 9252, 5394, 1433, 5585, 7626, 3029,
4452, 1015, 9813, 5396, 4223, 4715, 6426, 5932, 2410, 9826, 6831,
9340, 2511, 4845, 2052, 4822, 4333, 6610, 1111, 9843, 8443, 8423,
8523, 4263, 212, 2208, 6403, 5392, 5583, 3019, 4449])
example_vector = pd.DataFrame({
"word": vectorizer.get_feature_names_out()[tfidf_vectors[0, :].indices],
"tfidf": tfidf_vectors[0, :].data
})
example_vector
| word | tfidf | |
|---|---|---|
| 0 | to say that | 0.138789 |
| 1 | in spain and | 0.135125 |
| 2 | the most expensive | 0.147325 |
| 3 | we did not | 0.117090 |
| 4 | we should have | 0.149467 |
| ... | ... | ... |
| 70 | sat | 0.099373 |
| 71 | once | 0.099498 |
| 72 | outside | 0.084545 |
| 73 | from | 0.055708 |
| 74 | looked | 0.092127 |
75 rows × 2 columns
This time we will start right away with a classification model:
21.3.2. Logistic Regression model#
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(max_iter=300) # don't worry it also works without setting max_iter
model.fit(tfidf_vectors, y_train)
C:\Users\flori\anaconda3\envs\ai_smart_health\lib\site-packages\sklearn\linear_model\_logistic.py:458: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
LogisticRegression(max_iter=300)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
LogisticRegression(max_iter=300)
tfidf_vectors_test = vectorizer.transform(X_test)
predictions = model.predict(tfidf_vectors_test)
np.round(predictions[:20], 1)
array([4, 5, 4, 5, 4, 5, 5, 5, 5, 5, 5, 5, 4, 5, 5, 3, 5, 5, 5, 5],
dtype=int64)
y_test[:20].values
array([5, 5, 4, 5, 3, 5, 5, 5, 5, 4, 5, 5, 4, 5, 5, 3, 5, 5, 5, 5],
dtype=int64)
sb.histplot(predictions - y_test)
plt.xlabel("prediction error")
Text(0.5, 0, 'prediction error')
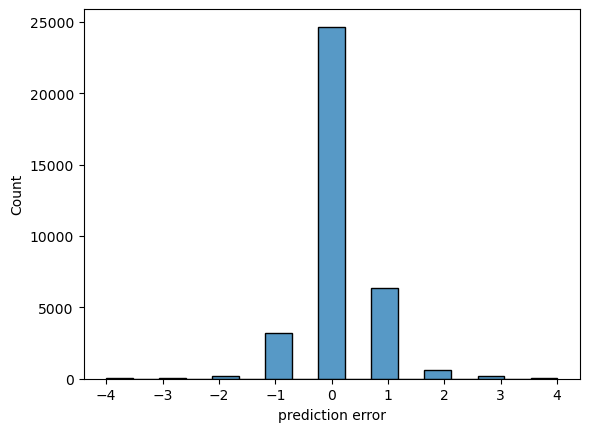
# mean absolute error:
np.abs(predictions - y_test).mean()
0.34684761096974837
from sklearn.metrics import confusion_matrix, classification_report
cm = confusion_matrix(y_test, predictions, labels=model.classes_)
# Plotting the confusion matrix with a heatmap
plt.figure(figsize=(9,7))
sb.heatmap(cm, annot=True, fmt='d',
cmap='Blues',
xticklabels=model.classes_,
yticklabels=model.classes_,
vmax=5000
)
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.title('Confusion Matrix')
plt.show()
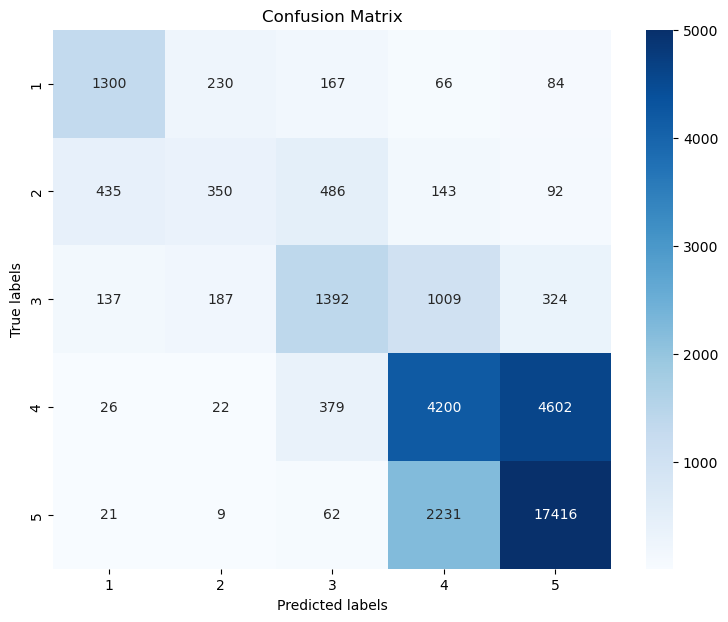
21.3.3. Did the 2-grams and 3-grams help?#
Well, the prediction accuracy only got slightly better. So, it seems to have some effect, but nothing spectacular. However, this is not a general finding and might look very differently for other datasets or problems.
We can now also look at the ngrams that have the largest impact on the model predictions:
ngrams = pd.DataFrame({"ngram": vectorizer.get_feature_names_out(),
"weight": model.coef_[0]
})
ngrams.sort_values("weight")
| ngram | weight | |
|---|---|---|
| 2008 | delicious | -5.679471 |
| 2477 | excellent | -5.174349 |
| 8694 | very good | -4.929491 |
| 7185 | tasty | -3.620315 |
| 8954 | was good | -3.569174 |
| ... | ... | ... |
| 3619 | horrible | 5.512549 |
| 1015 | avoid | 5.905717 |
| 6344 | rude | 5.934622 |
| 9826 | worst | 6.540459 |
| 7215 | terrible | 7.033302 |
10000 rows × 2 columns
Here, too, we find only very few 2-grams in the top-20 and bottom-20 lists. Most of the times, the model still seems to judge the reviews based on individual words.
ngrams.sort_values("weight").head(20)
| ngram | weight | |
|---|---|---|
| 2008 | delicious | -5.679471 |
| 2477 | excellent | -5.174349 |
| 8694 | very good | -4.929491 |
| 7185 | tasty | -3.620315 |
| 8954 | was good | -3.569174 |
| 2987 | friendly | -3.554020 |
| 1272 | bit | -3.392447 |
| 248 | amazing | -3.362312 |
| 7327 | the best | -3.300674 |
| 4991 | nice | -3.179749 |
| 967 | atmosphere | -2.883584 |
| 5066 | not bad | -2.815060 |
| 1215 | best | -2.774438 |
| 4385 | little | -2.698092 |
| 8959 | was great | -2.671645 |
| 5714 | perfect | -2.630462 |
| 4486 | loved | -2.577662 |
| 6117 | reasonable | -2.553251 |
| 2574 | fantastic | -2.466228 |
| 4492 | lovely | -2.462175 |
from sklearn.metrics import confusion_matrix, classification_report
print(confusion_matrix(y_test, predictions))
print(classification_report(y_test, predictions))
[[ 1300 230 167 66 84]
[ 435 350 486 143 92]
[ 137 187 1392 1009 324]
[ 26 22 379 4200 4602]
[ 21 9 62 2231 17416]]
precision recall f1-score support
1 0.68 0.70 0.69 1847
2 0.44 0.23 0.30 1506
3 0.56 0.46 0.50 3049
4 0.55 0.46 0.50 9229
5 0.77 0.88 0.82 19739
accuracy 0.70 35370
macro avg 0.60 0.55 0.56 35370
weighted avg 0.68 0.70 0.68 35370
21.3.4. Confusion matrix#
The confusion matrix can tell us a lot about where the model works well and where it fails. Often is is more accessible if the matrix is plotted, for instance using seaborns heatmap.
cm = confusion_matrix(y_test, predictions, labels=model.classes_)
# Plotting the confusion matrix with a heatmap
plt.figure(figsize=(9,7))
sb.heatmap(cm, annot=True, fmt='d',
cmap='Blues',
xticklabels=model.classes_,
yticklabels=model.classes_)
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.title('Confusion Matrix')
plt.show()
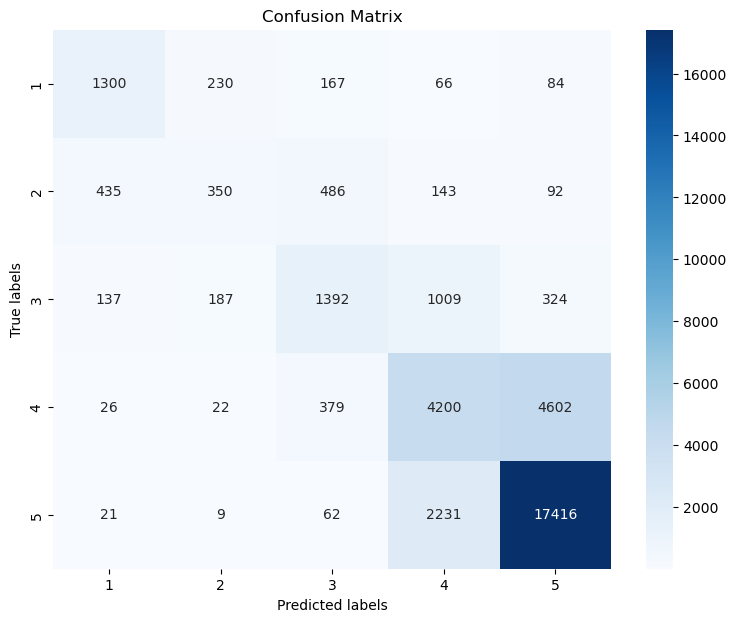
21.4. Find similar documents with tfidf#
So far, we used the tfidf-vectors as feature vectors to train machine learning models. As we just saw, this works very well to predict review rating or to classify documents as positive/negative (=sentiment analysis).
But there is more we can do with tfidf vectors. Why not use the vectors to compute distances or similarities? This way, we can search for the most similar documents in a corpus!
vectorizer = TfidfVectorizer(min_df=10, max_df=0.2,
max_features=50000,
ngram_range=(1, 3))
tfidf_vectors = vectorizer.fit_transform(X_train)
tfidf_vectors.shape
(141478, 50000)
tfidf_vectors.shape
(141478, 50000)
X_train.shape
(141478,)
21.4.1. Compare one vector to all other vectors#
Even though we here deal with very large vectors, computing similarities or angles between these vectors is compuationally very efficient. This means, we can simply compare a the tfidf vector of a given text to all > 140,000 documents in virtually no time!
In order for this to work, however, we should not rely on for-loops. Those are inherently slow in Python. We rather use optimized functions for this such as from sklear.metrics.pairwise.
from sklearn.metrics.pairwise import cosine_similarity
review_id = -11#-9#-2
query_vector = tfidf_vectors[review_id, :]
cosine_similarities = cosine_similarity(query_vector, tfidf_vectors).flatten()
cosine_similarities.shape
(141478,)
np.sort(cosine_similarities)[::-1]
array([1. , 0.36692149, 0.31812401, ..., 0. , 0. ,
0. ])
np.argsort(cosine_similarities)[::-1]
array([141467, 94876, 91939, ..., 95683, 43090, 104856], dtype=int64)
top5_idx = np.argsort(cosine_similarities)[::-1][1:6]
top5_idx
array([ 94876, 91939, 103516, 47460, 51098], dtype=int64)
Let us now look at the results of our search by displaying the top-5 most similar documents (according to the cosine score on the tfidf-vectors). This usually doesn’t work perfectly, but it does work to quite some extent. Try it out yourself and have a look at what documents this finds for you!
print("\n****Original document:****")
print(X_train.iloc[review_id])
for i in top5_idx:
print(f"\n----Document with similarity {cosine_similarities[i]:.3f}:----")
print(X_train.iloc[i])
****Original document:****
The food was great, the staff were friendly. The place was not crowded. The location was very convenient, while hidden from the hustle and bustle.
----Document with similarity 0.367:----
Takes you away from the hustle and bustle of the city ! Lovely setting.Recommend the sangria cocktails.
----Document with similarity 0.318:----
Cute little spot away from the hustle and bustle. We enjoyed the most delicious little cake (Tigre chocolate) and hot chocolate. Friendly service as well!
----Document with similarity 0.309:----
Stopped off for a quick drink, great little place away from the hustle and bustle. Tasty complimentary tortilla, didn't have a meal, but food looked great Would come back.
----Document with similarity 0.307:----
This taberna is nestled away from the hustle and bustle, but close to Palacio Real. Very authentic and local. Go hungry, cocido madrileño is not for the faint of heart.
----Document with similarity 0.298:----
Perfect dinner spot in La Latina, a little ways away from the hustle and bustle of this barrio. The service was above par and the food delicious. Will definitely be back!
21.5. Word Vectors: Word2Vec and Co#
Tfidf vectors are a rather basic, but still often used, technique. Arguably, this is because they are based on relatively simple statistics and easy to compute. They typically do a good job in weighing words according to their importance in a larger corpus and allow us to ignore words with low distriminative power (for instance so-called stopwords such as “a”, “the”, “that”, …).
With n-grams we can even go one step further and also count sentence pieces longer than one word, which allows to also take some grammar or negations into account. The price, however, is that we have to restrict the number of n-grams to avoid exploding vector sizes.
While TF-IDF vectors and n-grams serve as powerful techniques to represent and manipulate text data, they have limitations. These methods essentially treat words as individual, isolated units, devoid of any context or relation to other words. In other words, they lack the ability to capture the semantic meanings of words and the linguistic context in which they are used.
Take these two sentences as an example:
(1) The customer likes cake with a cappuccino.
(2) The client loves to have a cookie and a coffee.
We will immediately identify that both sentences speak of very similar things. But if you look at the words in both sentences you will realize that only “The” and “a” are found in both. And, as we have seen in the tfidf-part, such words tell very little about the sentence content. All other words, however, only occur in one or the other sentence. Tfidf-vectors would compute a zero similarity here.
This is where we come to word vectors. Word vectors, also known as word embeddings, are mathematical representations of words in a high-dimensional space where the semantic similarity between words corresponds to the geometric distance in the embedding space. Simply put, similar words are close together, and dissimilar words are farther apart. If done well, this should show that “cookie” and “cake” are not the same word, but mean something very related.
The most prominent example of such a technique is Word2Vec [Mikolov et al., 2013][Mikolov et al., 2013].
#!pip install gensim
import nltk
tokenizer = nltk.tokenize.TreebankWordTokenizer()
stemmer = nltk.stem.WordNetLemmatizer()
def process_document(doc):
"""Convert document to lemmas."""
tokens = tokenizer.tokenize(doc)
tokens = [x.strip(".,;:!? ") for x in tokens]
return [stemmer.lemmatize(w) for w in tokens]
from tqdm.notebook import tqdm
sentences = [process_document(doc) for doc in tqdm(X_train.values)]
len(sentences)
141478
We will now train our own Word2Vec model using Gensim, see also documentation.
from gensim.models import Word2Vec
# Assume 'sentences' is a list of lists of tokenized sentences
model = Word2Vec(sentences,
vector_size=200,
window=5,
min_count=2,
workers=4)
model.save("word2vec_madrid_reviews.model")
vector = model.wv['delicious'] # get numpy vector of a word
vector
array([-2.03538680e+00, 2.52757788e-01, -6.78372085e-01, -1.26871383e+00,
-1.08166724e-01, 8.22216213e-01, 3.38415295e-01, 7.98148632e-01,
-9.87190962e-01, -9.55492854e-01, 4.07470644e-01, 1.39118874e+00,
1.67936873e+00, -1.62421167e-01, -1.18595815e+00, 2.57541704e+00,
-5.80342531e-01, 1.33421934e+00, 2.37748718e+00, -1.43586814e+00,
-1.04479599e+00, 6.39563650e-02, -8.97780657e-01, 6.41878784e-01,
-1.74520206e+00, 4.68130469e-01, 8.02812040e-01, -9.29517210e-01,
-7.74732411e-01, -8.87739718e-01, -5.06934702e-01, -3.21538508e-01,
-4.80596572e-02, -1.68594670e+00, -2.41771966e-01, -4.61565822e-01,
-2.03054279e-01, 9.59063053e-01, -4.65506434e-01, 1.38559628e+00,
-4.67663795e-01, -5.63467026e-01, -1.44417775e+00, -1.22851729e+00,
1.17849803e+00, -1.26880860e+00, -5.07019520e-01, 3.69102329e-01,
2.92213416e+00, -4.93991584e-01, -6.48129582e-01, 1.70414066e+00,
-1.23612189e+00, -1.72287583e+00, 1.15597653e+00, 1.44868660e+00,
-1.22250819e+00, 2.37475419e+00, 6.53695226e-01, 2.05163908e+00,
-3.08574414e+00, 1.66374397e+00, -2.80261766e-02, 6.86524808e-01,
1.53102946e+00, 6.65094972e-01, -5.36559187e-02, -7.84830332e-01,
7.35198379e-01, 1.32039881e+00, 7.09394872e-01, -1.21944356e+00,
8.04880083e-01, -2.76637882e-01, -6.61925673e-01, -1.25887072e+00,
1.19793057e+00, 4.21494067e-01, 7.66302586e-01, 9.96498585e-01,
5.08949719e-02, 1.45889115e+00, 5.01284957e-01, -7.05735385e-01,
1.15695286e+00, -2.63115740e+00, 6.68963552e-01, -1.25631428e+00,
8.86810184e-01, 6.45234525e-01, 1.62897801e+00, 6.84916005e-02,
1.24690199e+00, -4.46591347e-01, -1.15185416e+00, 5.72938859e-01,
1.25214541e+00, -1.03020048e+00, 1.85466862e+00, 2.71878541e-01,
6.15206361e-01, 1.77544081e+00, 1.54688907e+00, -3.51346731e+00,
2.00846910e+00, 2.17208838e+00, -5.17885029e-01, -5.46077728e-01,
-2.82651377e+00, -8.21791515e-02, 2.36416310e-01, -6.74597442e-01,
-8.51826787e-01, -3.59785527e-01, -1.56974423e+00, 9.27218020e-01,
-2.02717376e+00, 1.95397782e+00, 7.02663004e-01, -1.02236593e+00,
6.56838715e-01, 6.73914135e-01, -3.00290734e-01, -9.34027076e-01,
-8.00638616e-01, -1.32641673e-01, -7.23512411e-01, -1.51655793e+00,
-8.64614844e-01, 7.01261044e-01, 1.04395604e+00, 1.31523907e+00,
8.43236089e-01, -2.57687283e+00, -1.49496460e+00, -4.15781051e-01,
-5.65135837e-01, 2.03486538e+00, 1.17266095e+00, -2.50355184e-01,
1.85218894e+00, 5.07799566e-01, 1.23914981e+00, -4.94150430e-01,
2.27533412e+00, -2.61036470e-03, -3.87329668e-01, -1.11296475e-01,
-1.18795252e+00, 3.70148182e-01, 1.59401250e+00, -1.83947122e+00,
-2.73712277e+00, 4.71669245e+00, 1.95886984e-01, -4.84028697e-01,
9.64134216e-01, 2.53249586e-01, -2.59700298e+00, -2.38229573e-01,
-1.69923174e+00, 3.20591122e-01, -2.14936686e+00, -5.11169016e-01,
7.22345829e-01, 1.10016990e+00, 2.35557246e+00, -7.25124359e-01,
-1.31868494e+00, -6.81534111e-01, -4.91266608e-01, 1.32315159e+00,
9.05143797e-01, 9.32789594e-02, -6.45776391e-01, -1.09242570e+00,
-3.32741797e-01, -2.71128982e-01, -1.77400219e+00, 1.17381942e+00,
-3.83675754e-01, -1.02986455e+00, -2.15794826e+00, -9.86504018e-01,
1.52942610e+00, 7.36541212e-01, -3.30162406e+00, 1.44280720e+00,
-1.08328497e+00, 5.31407893e-02, -1.49774420e+00, -2.06774545e+00,
-1.72131769e-02, -1.64670253e+00, 1.24993122e+00, -2.00452232e+00,
5.38596213e-01, -4.72304463e-01, 1.02590454e+00, 7.42713094e-01],
dtype=float32)
model.wv.most_similar('delicious', topn=10)
[('tasty', 0.8175682425498962),
('delicious.', 0.7884759306907654),
('yummy', 0.7805776000022888),
('amazing', 0.7275819778442383),
('fantastic', 0.7188233137130737),
('divine', 0.7097207903862),
('exquisite', 0.6883265376091003),
('superb', 0.6864668130874634),
('incredible', 0.6731298565864563),
('phenomenal', 0.6625100374221802)]
model.wv.most_similar('pizza', topn=10)
[('Pizza', 0.687938392162323),
('hamburger', 0.6807577610015869),
('burger', 0.6770654916763306),
('pasta', 0.6611385345458984),
('carbonara', 0.6239833831787109),
('burrito', 0.589520275592804),
('pizza.', 0.5812183022499084),
('margarita', 0.5620388388633728),
('crust', 0.5615034699440002),
('calzone', 0.550714910030365)]
model.wv.most_similar('horrible', topn=10)
[('terrible', 0.8658505082130432),
('awful', 0.8121690154075623),
('bad', 0.7098363041877747),
('appalling', 0.6666131615638733),
('disgusting', 0.652198851108551),
('poor', 0.6406951546669006),
('shocking', 0.6216946840286255),
('okay', 0.6188369989395142),
('dreadful', 0.6177916526794434),
('Terrible', 0.6082724928855896)]
model.wv.most_similar('friendly', topn=10)
[('friendly.', 0.764923095703125),
('courteous', 0.7515475153923035),
('polite', 0.7410220503807068),
('welcoming', 0.7141723036766052),
('cordial', 0.7002096176147461),
('attentive', 0.6988195180892944),
('personable', 0.6342913508415222),
('gracious', 0.6272123456001282),
('professional', 0.6221848726272583),
('freindly', 0.6203247308731079)]
model.wv.most_similar('chocolate', topn=10)
[('brownie', 0.7869287729263306),
('cheesecake', 0.7738447189331055),
('carrot', 0.7625924348831177),
('caramel', 0.7542667388916016),
('crepe', 0.742887020111084),
('flan', 0.7408572435379028),
('custard', 0.7393072843551636),
('tiramisu', 0.7378472685813904),
('icecream', 0.7375630736351013),
('tart', 0.7370063662528992)]
model.wv.most_similar('coffee', topn=10)
[('tea', 0.7526535987854004),
('croissant', 0.7297593355178833),
('cappuccino', 0.7134137153625488),
('coffee.', 0.6472688913345337),
('churros', 0.6273057460784912),
('coffe', 0.6237097382545471),
('juice', 0.6207398176193237),
('breakfast', 0.6145669221878052),
('latte', 0.6066522002220154),
('espresso', 0.5939613580703735)]
21.6. Alternative short-cuts#
Training your own Word2Vec model is fun and sometimes also really helpful. Here it is quite OK for instance, because we have a relatively big text corpus (> 140,000 documents) with a clear general topic focus on restaurants and food.
Often, however, you simply may want to use a model that covers a language more broadly. Instead of training your own model on a much bigger corpus, we can simply use a model that was trained already, see for instance here on the Gensim website.
Another way is to use SpaCy. Its larger language models already contain word embeddings!
# Comment out and run the following to first download a large english model
#!python -m spacy download en_core_web_lg
import spacy
nlp = spacy.load("en_core_web_lg")
As we have seen before, SpaCy converts the text into tokens, but also does much more. We can look at different attributes of the tokens to extract the computed information. For instance:
.text: The original token text.has_vector: Does the token have a vector representation?.vector_norm: The L2 norm of the token’s vector (the square root of the sum of the values squared).is_oov: Out-of-vocabulary
tokens = nlp("dog cat banana afskfsd")
for token in tokens:
print(token.text, token.has_vector, token.vector_norm, token.is_oov)
dog True 75.254234 False
cat True 63.188496 False
banana True 31.620354 False
afskfsd False 0.0 True
tokens[0].vector
array([ 1.2330e+00, 4.2963e+00, -7.9738e+00, -1.0121e+01, 1.8207e+00,
1.4098e+00, -4.5180e+00, -5.2261e+00, -2.9157e-01, 9.5234e-01,
6.9880e+00, 5.0637e+00, -5.5726e-03, 3.3395e+00, 6.4596e+00,
-6.3742e+00, 3.9045e-02, -3.9855e+00, 1.2085e+00, -1.3186e+00,
-4.8886e+00, 3.7066e+00, -2.8281e+00, -3.5447e+00, 7.6888e-01,
1.5016e+00, -4.3632e+00, 8.6480e+00, -5.9286e+00, -1.3055e+00,
8.3870e-01, 9.0137e-01, -1.7843e+00, -1.0148e+00, 2.7300e+00,
-6.9039e+00, 8.0413e-01, 7.4880e+00, 6.1078e+00, -4.2130e+00,
-1.5384e-01, -5.4995e+00, 1.0896e+01, 3.9278e+00, -1.3601e-01,
7.7732e-02, 3.2218e+00, -5.8777e+00, 6.1359e-01, -2.4287e+00,
6.2820e+00, 1.3461e+01, 4.3236e+00, 2.4266e+00, -2.6512e+00,
1.1577e+00, 5.0848e+00, -1.7058e+00, 3.3824e+00, 3.2850e+00,
1.0969e+00, -8.3711e+00, -1.5554e+00, 2.0296e+00, -2.6796e+00,
-6.9195e+00, -2.3386e+00, -1.9916e+00, -3.0450e+00, 2.4890e+00,
7.3247e+00, 1.3364e+00, 2.3828e-01, 8.4388e-02, 3.1480e+00,
-1.1128e+00, -3.5598e+00, -1.2115e-01, -2.0357e+00, -3.2731e+00,
-7.7205e+00, 4.0948e+00, -2.0732e+00, 2.0833e+00, -2.2803e+00,
-4.9850e+00, 9.7667e+00, 6.1779e+00, -1.0352e+01, -2.2268e+00,
2.5765e+00, -5.7440e+00, 5.5564e+00, -5.2735e+00, 3.0004e+00,
-4.2512e+00, -1.5682e+00, 2.2698e+00, 1.0491e+00, -9.0486e+00,
4.2936e+00, 1.8709e+00, 5.1985e+00, -1.3153e+00, 6.5224e+00,
4.0113e-01, -1.2583e+01, 3.6534e+00, -2.0961e+00, 1.0022e+00,
-1.7873e+00, -4.2555e+00, 7.7471e+00, 1.0173e+00, 3.1626e+00,
2.3558e+00, 3.3589e-01, -4.4178e+00, 5.0584e+00, -2.4118e+00,
-2.7445e+00, 3.4170e+00, -1.1574e+01, -2.6568e+00, -3.6933e+00,
-2.0398e+00, 5.0976e+00, 6.5249e+00, 3.3573e+00, 9.5334e-01,
-9.4430e-01, -9.4395e+00, 2.7867e+00, -1.7549e+00, 1.7287e+00,
3.4942e+00, -1.6883e+00, -3.5771e+00, -1.9013e+00, 2.2239e+00,
-5.4335e+00, -6.5724e+00, -6.7228e-01, -1.9748e+00, -3.1080e+00,
-1.8570e+00, 9.9496e-01, 8.9135e-01, -4.4254e+00, 3.3125e-01,
5.8815e+00, 1.9384e+00, 5.7294e-01, -2.8830e+00, 3.8087e+00,
-1.3095e+00, 5.9208e+00, 3.3620e+00, 3.3571e+00, -3.8807e-01,
9.0022e-01, -5.5742e+00, -4.2939e+00, 1.4992e+00, -4.7080e+00,
-2.9402e+00, -1.2259e+00, 3.0980e-01, 1.8858e+00, -1.9867e+00,
-2.3554e-01, -5.4535e-01, -2.1387e-01, 2.4797e+00, 5.9710e+00,
-7.1249e+00, 1.6257e+00, -1.5241e+00, 7.5974e-01, 1.4312e+00,
2.3641e+00, -3.5566e+00, 9.2066e-01, 4.4934e-01, -1.3233e+00,
3.1733e+00, -4.7059e+00, -1.2090e+01, -3.9241e-01, -6.8457e-01,
-3.6789e+00, 6.6279e+00, -2.9937e+00, -3.8361e+00, 1.3868e+00,
-4.9002e+00, -2.4299e+00, 6.4312e+00, 2.5056e+00, -4.5080e+00,
-5.1278e+00, -1.5585e+00, -3.0226e+00, -8.6811e-01, -1.1538e+00,
-1.0022e+00, -9.1651e-01, -4.7810e-01, -1.6084e+00, -2.7307e+00,
3.7080e+00, 7.7423e-01, -1.1085e+00, -6.8755e-01, -8.2901e+00,
3.2405e+00, -1.6108e-01, -6.2837e-01, -5.5960e+00, -4.4865e+00,
4.0115e-01, -3.7063e+00, -2.1704e+00, 4.0789e+00, -1.7973e+00,
8.9538e+00, 8.9421e-01, -4.8128e+00, 4.5367e+00, -3.2579e-01,
-5.2344e+00, -3.9766e+00, -2.1979e+00, 3.5699e+00, 1.4982e+00,
6.0972e+00, -1.9704e+00, 4.6522e+00, -3.7734e-01, 3.9101e-02,
2.5361e+00, -1.8096e+00, 8.7035e+00, -8.6372e+00, -3.5257e+00,
3.1034e+00, 3.2635e+00, 4.5437e+00, -5.7290e+00, -2.9141e-01,
-2.0011e+00, 8.5328e+00, -4.5064e+00, -4.8276e+00, -1.1786e+01,
3.5607e-01, -5.7115e+00, 6.3122e+00, -3.6650e+00, 3.3597e-01,
2.5017e+00, -3.5025e+00, -3.7891e+00, -3.1343e+00, -1.4429e+00,
-6.9119e+00, -2.6114e+00, -5.9757e-01, 3.7847e-01, 6.3187e+00,
2.8965e+00, -2.5397e+00, 1.8022e+00, 3.5486e+00, 4.4721e+00,
-4.8481e+00, -3.6252e+00, 4.0969e+00, -2.0081e+00, -2.0122e-01,
2.5244e+00, -6.8817e-01, 6.7184e-01, -7.0466e+00, 1.6641e+00,
-2.2308e+00, -3.8960e+00, 6.1320e+00, -8.0335e+00, -1.7130e+00,
2.5688e+00, -5.2547e+00, 6.9845e+00, 2.7835e-01, -6.4554e+00,
-2.1327e+00, -5.6515e+00, 1.1174e+01, -8.0568e+00, 5.7985e+00],
dtype=float32)
nlp1 = nlp(X_train[0])
nlp2 = nlp(X_train[1])
nlp1.similarity(nlp1)
1.0
nlp1.similarity(nlp2)
0.732720161085499
nlp1
The menu of Yakuza is a bit of a lottery, some plates are really good (like most of the sushi rolls) and instead some others are terrible ( the pizza sushi and most of the fried starters). Taking this in consideration, it´s a great option if you feel like sushi and can avoid ordering from the rest of the menu. We even ordered for delivery more than once and the packaging they use is great.
nlp2
Check your bill when you cancel just in case you get an extra charge surprise on it There are no more words to describe my experience when I was there. Sad and poor experience!! Never return! Never again
21.6.1. Limitations and Extensions#
While Word2Vec is a powerful tool, it’s not without limitations. The main issue with Word2Vec (and similar models that derive their semantics based on the local usage context) is that they assign one vector per word. This becomes a problem for words with multiple meanings based on their context (homonyms and polysemes). To tackle such limitations, extensions like FastText and advanced methods such as GloVe (Global Vectors for Word Representation) and transformers like BERT (Bidirectional Encoder Representations from Transformers) have been proposed.
21.6.2. FastText#
FastText, also developed by Facebook, extends Word2Vec by treating each word as composed of character n-grams. So the vector for a word is made of the sum of these character n-grams. This allows the embeddings to capture the meaning of shorter words and suffixes/prefixes and understand new words once the character n-grams are learned.
21.6.3. GloVe#
GloVe, developed by Stanford, is another method to create word embeddings. While Word2Vec is a predictive model — a model that predicts context given a word, GloVe is a count-based model. It leverages matrix factorization techniques on the word-word co-occurrence matrix.
21.6.4. Transformers: BERT & GPT#
BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pretrained Transformer) models ushered in the era of transformers that not only consider local context but also take the entire sentence context into account to create word embeddings.
In conclusion, while TF-IDF and n-grams offer a solid start, word embeddings and transformers take the representation of words to the next level. By considering context and semantic meaning, they offer a more complete and robust method to work with text.