17. Machine Learning - Common Algorithms II (Linear Models)#
We first looked at k-nearest neighbors (k-NN) and applied it to a simple dataset by using the Scikit-Learn implementation. Scikit-Learn provides many more machine learning models, and all are relatively easy to use from a coding perspective.
The supervised models (see the Scikit-Learn guide) are usually handled in a very similar way. We first train a model using model.fit(X, y) where X is our training data and y our targets or labels. Predictions on new data X_new are generated using model.predict(X_new).
In most cases, the main difficulty is not the code part. It is the right choice of an algorithm and the proper preparation of the input data. One thing that can lead to quite embarrassing outcomes, but also to drastic failure of a project, is the use of machine learning models without a proper understanding of how they work. A good data scientist will develop an intuition over time for what type of models work well for a certain task and dataset. This is nothing that can be developed within a few days or weeks, but we can set a good starting point here.
17.1. Linear Models#
Linear models are a cornerstone of machine learning, offering a simple yet powerful approach for both regression and classification tasks. They are based on the principle of linear combination of input features to predict an output. These models are favored for their interpretability, computational efficiency, and the foundational role they play in understanding complex machine learning concepts.
17.2. Linear Regression#
Linear regression is one of the simplest and most fundamental machine learning algorithms. Whenever you had a calculator or a program to find a linear fit through many datapoints, that was, in principle, already a linear regression model. It is used for predictive modeling, specifically for forecasting a quantitative response based on one or more predictor variables (features). The essence of linear regression lies in fitting a linear equation to the observed data. The equation takes the form:
Here, \(y\) represents the dependent variable we aim to predict, \(x_1\), \(x_2\), … , \(x_n\) are the independent variables (features), \(\beta_0\) is the y-intercept, \(\beta_1\), \(\beta_2\),…,\(\beta_n\) are the coefficients that represent the weight of each feature in predicting the target variable, and \(\epsilon\) is the error term, capturing the difference between the observed and predicted values.
The goal of linear regression is to find the best-fitting line through the data points that minimizes the sum of the squared differences between the observed and predicted values, known as the least squares criterion.
But how does the algorithm learn from the data? Linear regression “learns” from the data by adjusting the coefficients (\(β\) values) to minimize the cost function, typically the mean squared error (MSE) between the predicted and actual values of the dependent variable. The learning process involves solving for the coefficients that result in the best fit. This can be achieved through various methods, including gradient descent or more direct mathematical approaches like the Ordinary Least Squares (OLS) method. Such a process is an iterative process, as illustrated in Fig. 17.1.
The illustrated example used one-dimensional data (\(x_1\)) which is used to model a one-dimensional label (\(y\)). Here, only \(\beta_0\) and \(\beta_1\) would need to be learned. In practice, however, most datasets we use will be of much higher dimensionality and the resulting models will have to learn many coefficients.
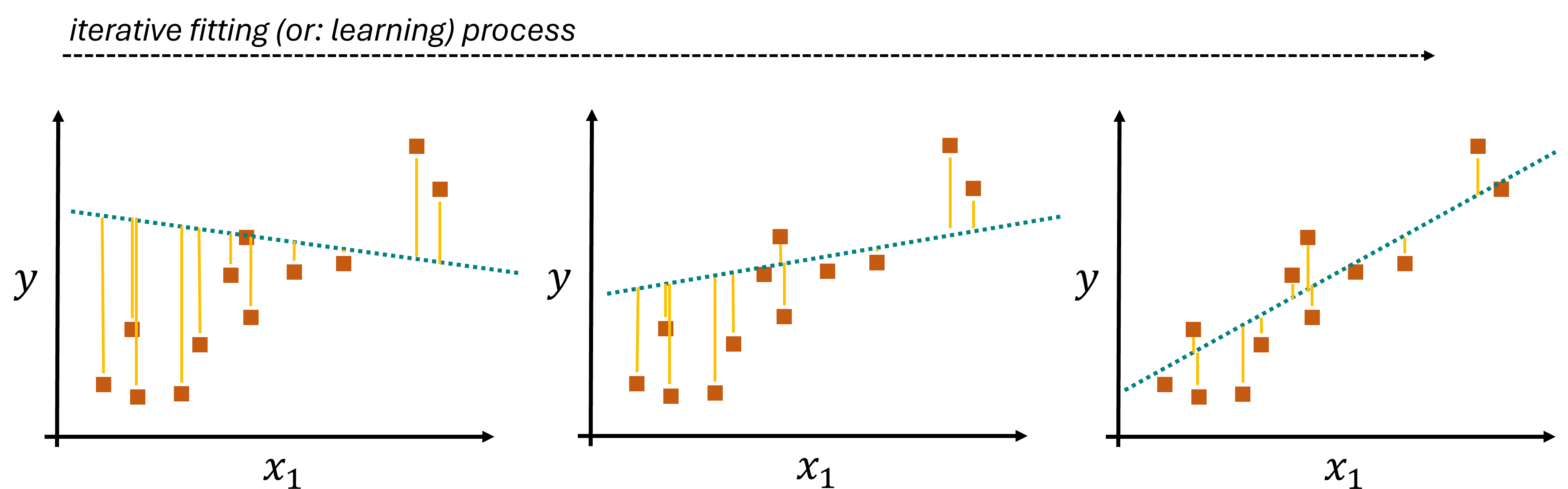
Fig. 17.1 The coefficients of the linear model are learned by an iterative optimization process. A common procedure for this is the minimization of the mean squared error (errors are indicated by the yellow lines).#
17.2.1. Pros, Cons, Caveats#
One of the main advantages of Linear Regression models lies in the simplicity of the concept. It is very easy to understand what such a model does, and computationally, it is very efficient.
Unlike k-NN, linear regression models learn one coefficient per input feature. As a result, such linear models are not sensitive to features of different scales, and rescaling is not required.
However, linear models come with some important limitations. Their main issue is, that they are often just too simple to describe data well enough because, very often, relationships between features or features and labels are not linear Fig. 17.2. And, in contrast to k-NN, linear models can output predictions that are nonsensical or impossible (e.g. negative heights, prices, physically impossible temperatures etc.). Since they will always output something, they also come at a risk of making overconfident predictions, so predictions for datapoints that are very different from all training samples.
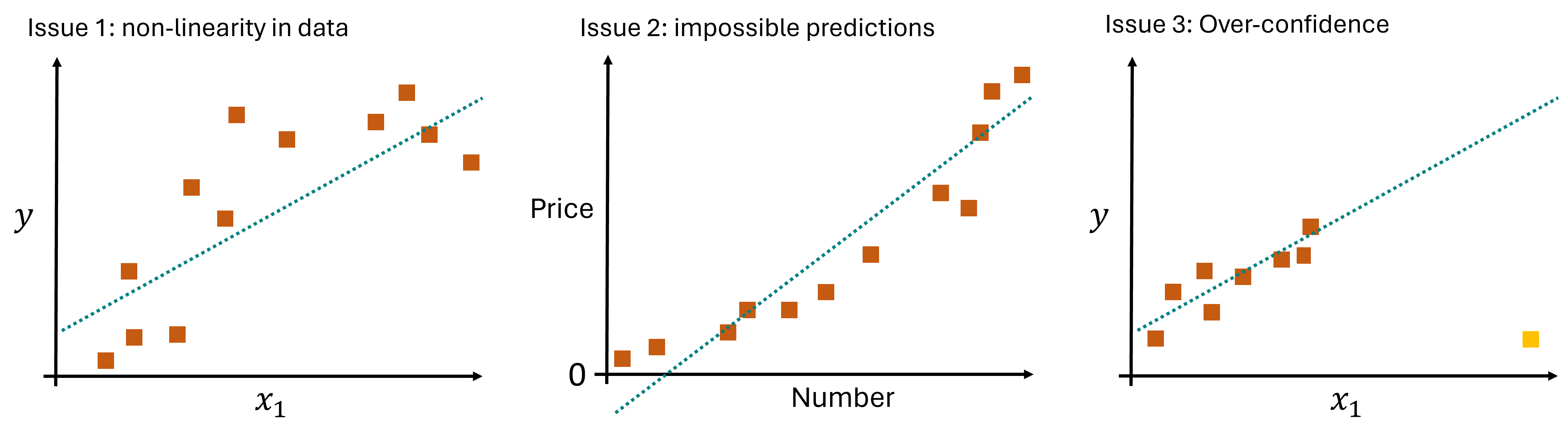
Fig. 17.2 The coefficients of the linear model are learned by an iterative optimization process. A common procedure for this is the minimization of the mean squared error (errors are indicated by the yellow lines).#
Pros:
Simplicity and interpretability: The linear regression model is straightforward to understand and interpret, making it an excellent starting point for predictive modeling.
Computational efficiency: It is computationally inexpensive to train and predict with linear regression, allowing it to handle large datasets effectively.
Continuous and categorical data: It can handle both types of data, with categorical variables often incorporated through dummy coding.
Cons:
Assumption of linearity: The biggest limitation is the assumption that there is a linear relationship between the dependent and independent variables. This assumption does not hold for many real-world scenarios.
Outliers sensitivity: Linear regression is sensitive to outliers in the data, which can significantly affect the regression line and coefficients.
Impossible predictions & Overconfidence: Linear models can easily output values far outsize the desired or possible ranges. This is here linked to over-confidence when data is used with the model that is far away from all training data.
17.3. Hands-on Example#
We here again work with the Penguin Dataset [Horst et al., 2020]. But instead of predicting the species (which is a categorical value), we will try to predict numerical values.
This will create a regression task instead of a classification task.
import os
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
import seaborn as sb
17.3.1. Data Inspection & Cleaning#
filename = "../datasets/penguins_size.csv" # contains some changes with respect to the original dataset!
data = pd.read_csv(filename)
data = data.dropna()
label_name = "flipper_length_mm"
y = data[label_name]
X = data.drop(["species", "island", label_name], axis=1)
X["sex"] = 1 * pd.get_dummies(X["sex"])["FEMALE"]
X = X.rename(columns={"sex": "female"})
X.head()
| culmen_length_mm | culmen_depth_mm | body_mass_g | female | |
|---|---|---|---|---|
| 0 | 39.1 | 18.7 | 3750.0 | 0 |
| 1 | 39.5 | 17.4 | 3800.0 | 1 |
| 2 | 40.3 | 18.0 | 3250.0 | 1 |
| 4 | 36.7 | 19.3 | 3450.0 | 1 |
| 5 | 39.3 | 20.6 | 3650.0 | 0 |
17.3.2. Train/Test split#
As done before, we will simply split the data into a training set and a test set.
from sklearn.model_selection import train_test_split
# Train-test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=0)
# Let's check the outcome dimensions
X_train.shape, X_test.shape, y_train.shape, y_test.shape
((250, 4), (84, 4), (250,), (84,))
17.3.3. Train a model (and make predictions)#
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(X_train, y_train)
LinearRegression()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
LinearRegression()
17.3.3.1. What has the model “learned”?#
Our model takes numerical input, in this case with 4 dimensions (4 features –> see X_train.shape).
Through the training, which here is simply an optimization of the linear fit, our model has then learned one coefficient per input. These are the before-mentioned values for \(\beta_1\) to \(\beta_4\) in this case.
model.coef_
array([ 0.56942041, -1.5552058 , 0.01114168, -0.02814116])
The model has also learned the y-intercept \(\beta_0\):
model.intercept_
156.04773034515802
Compute predictions
Just as before with the k-NN model, we can simply create predictions on any data of the expected size (here: 4 features).
predictions = model.predict(X_test)
predictions
array([193.36801925, 186.90095107, 186.96514261, 216.78177533,
192.5010084 , 218.96978654, 187.11302035, 188.36432361,
184.62538673, 223.42560836, 204.29932642, 195.77336369,
182.2866393 , 182.74081935, 185.65632772, 185.16122669,
190.24214572, 209.81139846, 196.76588675, 191.91914093,
190.01785114, 192.53351504, 212.30073619, 219.58809295,
226.64536711, 212.19702546, 222.7882205 , 224.88228114,
196.79434262, 194.28741805, 191.54089813, 190.14804443,
191.95268066, 187.10027097, 221.95745147, 187.2304965 ,
195.75156967, 199.25900799, 209.14328103, 189.30897673,
195.24710661, 186.65085722, 221.30229292, 207.25208685,
195.39348974, 218.42292117, 198.16769688, 222.22600408,
189.14585881, 187.70453709, 199.97435282, 191.37207844,
208.85914802, 186.89632311, 219.34255409, 191.10136301,
193.81986592, 189.7923519 , 193.03099497, 216.95602953,
193.49050434, 224.38722562, 187.15019287, 222.91529282,
198.19291897, 187.19884951, 188.94023249, 193.65535099,
186.75182794, 190.91060338, 194.4856158 , 198.11059563,
190.52188012, 202.63218985, 215.41547344, 212.7758582 ,
195.47410897, 213.25641471, 193.78951642, 202.3466731 ,
187.39539717, 216.12611255, 208.97056695, 197.21031903])
17.3.4. Model evaluation#
Unlike for classification, we don’t have a simpe distinction between right (correct class was predicted) and wrong. In most cases, we will not even expect our model to make perfect predictions, but predictions which in most cases come very close to the true values.
This can be tested in several ways. Here, we will do two very simple and easy-to-read tests. First, we just plot the predicted values against the true values in a scatter plot:
fig, ax = plt.subplots(figsize=(5, 5))
ax.scatter(predictions, y_test)
ax.set_ylabel("True label")
ax.set_xlabel("Predicted label")
Text(0.5, 0, 'Predicted label')
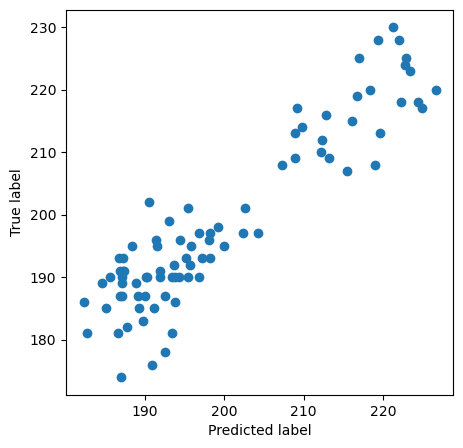
We can also look at the prediction errors, which simply is y_test - predictions.
A histogram can quickly show us by how far our model predictions are off.
fig, ax = plt.subplots(figsize=(7, 4))
ax.hist(y_test - predictions, bins=15, rwidth=0.8)
ax.set_title("Prediction errors")
Text(0.5, 1.0, 'Prediction errors')
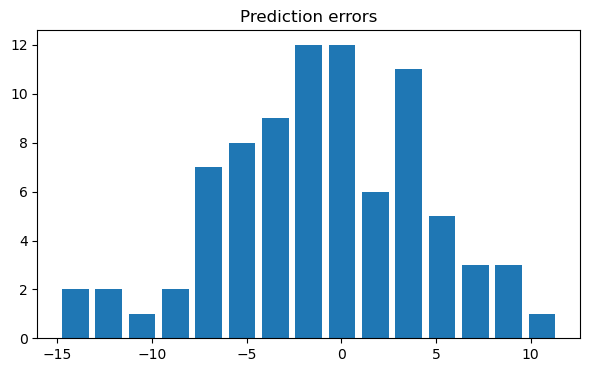
In this example we see that most predictions are off by no more than +- 5.