12. Clustering#
Clustering (or cluster analysis) is the process of organizing a collection of data points into groups, referred to as clusters, based on their similarities. This method plays a crucial role within the data science workflow (see Section 7), serving multiple purposes across different stages of a project. Primarily, clustering aids in data exploration, allowing us to uncover underlying patterns, group similar data points, and generate insights that are not immediately apparent. Furthermore, clustering can be employed as a technique to model data, facilitate anomaly detection, and reduce dimensionality.
12.1. Introduction#
12.1.1. What is clustering?#
Clustering aims to identify a natural or meaningful division of data points into a number of groups, or clusters. There is a commonly shared intuition that a “good” cluster is one where all datapoints have high similarity or share some important properties. In some cases, this can indeed be simple in the sense that most people would intuitively agree on a suitable division into clusters, such as illustrated in Fig. 12.1. At least, I haven’t yet had a student who gave an answer that was different from “three” when asked for the number of groups in this dataset. In practice, however, those question will not be answered by any of my students, nor by me. We will use a range of different clustering algorithms to do the clustering for us.
In this section, we will explain and apply some of the most common clustering algorithms, including KMeans and DBSCAN. We will discuss their operational mechanisms, evaluate their distinct advantages, and address their limitations. The application of these algorithms will be demonstrated on synthetic datasets to illustrate their practical implementation and the interpretation of results.
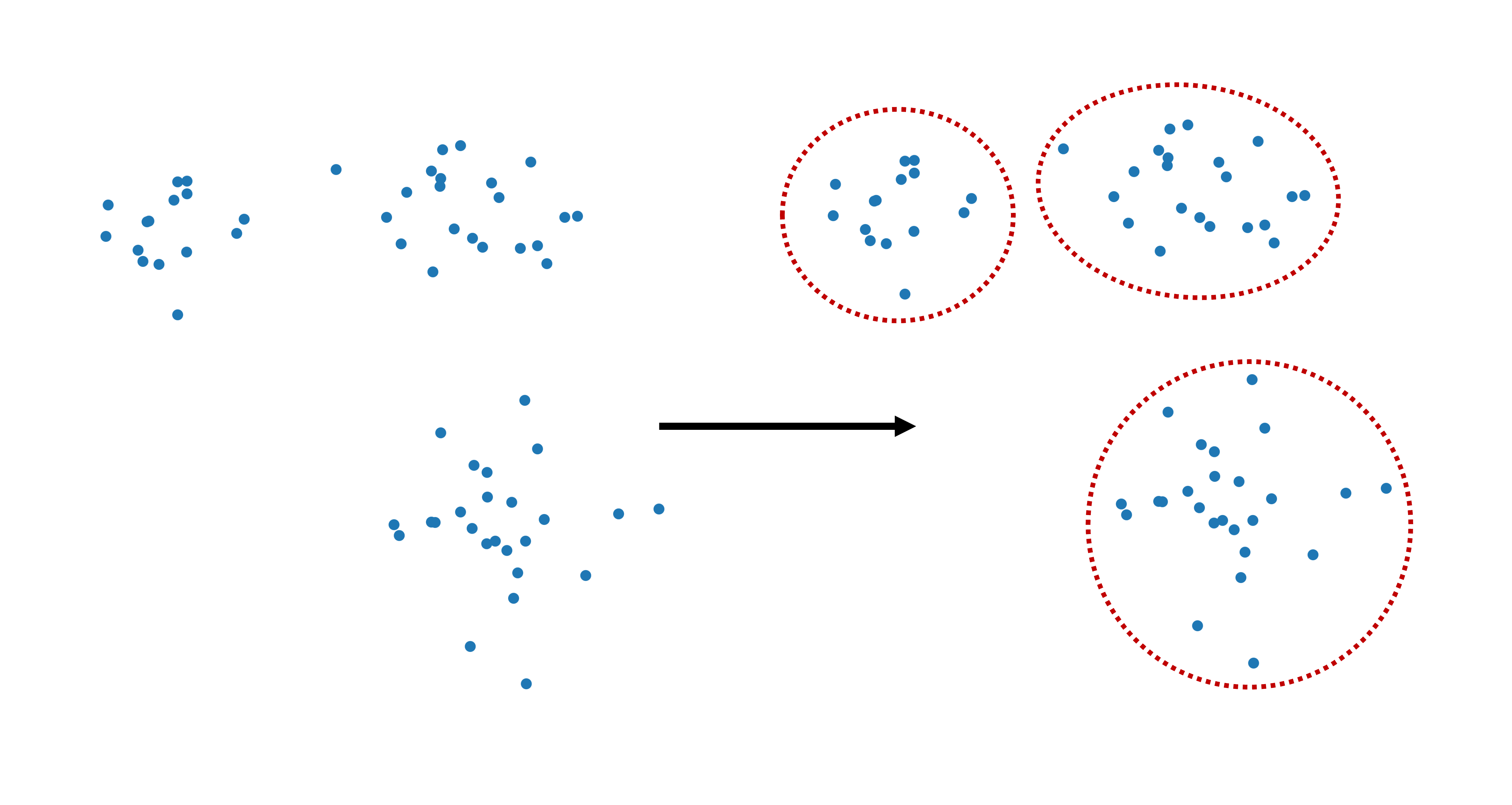
Fig. 12.1 Clustering refers to dividing data points into separate groups or: clusters.#
Next, we create such a synthetic dataset with three clusters. This dataset consists of three groups of points, each generated from a different Gaussian distribution. Each group of points has its own mean and standard deviation along the x and y axes.
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
# optional, only to avoid KMeans warning on Windows (too few chunks compared to threads)
import os
os.environ["OMP_NUM_THREADS"] = "1"
# Set the ggplot style (optional)
plt.style.use("ggplot")
clusters = [(15, 0.5, 0.5, 1.5, -0.7),
(21, 0.8, 0.5, -2.1, -1.2),
(25, 0.8, 0.7, -2.6, 2.3)]
np.random.seed(42)
data = np.zeros((0, 2))
for (n_points, x_scale, y_scale, x_offset, y_offset) in clusters:
xpts = np.random.randn(n_points) * x_scale + x_offset
ypts = np.random.randn(n_points) * y_scale + y_offset
data = np.vstack((data, np.vstack((xpts, ypts)).T))
We visualize the dataset using pyplot. The dataset contains three visually distinct clusters.
fig, ax = plt.subplots(figsize=(7, 7), dpi=300)
ax.scatter(data[:,0], data[:,1], color="teal")
plt.axis('off')
plt.show()

Assigning the three clusters in this case does not exactly feel like rocket science. We could all do this manually with a pen in no time. So, why bother to use - let alone understand or develop - algorithms for this task?
There are two reasons why the shown figure makes the task look easy. First, the points are distributed in a way that immediately suggests clear boundaries or center positions. Obviously, not all cases will look that simple. More importantly, however, is that in most cases our datapoints will be nothing we can simply “look” at, or draw lines around because the data won’t be two-dimensional. The number of features (or, in a table: columns) is what sets the number of dimensions of our data. And this will rarely ever be just two. But for datapoints which are 4D, 5D, 6D, 10D, or 100D, manually assigning clusters is not an option.
There are more reasons to rather search for a good algorithm than to assign clusters manually. Algorithms allow to cluster much larger datasets. And, in some cases, they will give consistent, reproducible results, i.e., they will assign each element the same cluster whenever we run the algorithm again. We will later see, that this is not true for all clustering algorithms.
12.1.2. Why do we want to cluster data?#
Clustering data serves as a fundamental technique in a data scientist’s toolkit beyond simply managing multidimensional data. It facilitates the discovery of intrinsic patterns and structures hidden within data, particularly in high-dimensional datasets. These patterns reveal relationships, categories, and subclasses that may not be evident through direct observation, providing insights that are critical for informed decision-making.
Additionally, clustering helps to summarize large datasets by forming representative groups or clusters, making it more efficient for data compression and simplification. This simplification is essential for further analysis, visualization, and reporting. For example, in customer segmentation, clustering identifies groups of consumers with similar behaviors, enabling more targeted and effective marketing strategies.
Another crucial application of clustering is anomaly detection. By defining what constitutes ‘normal’ behavior within a cluster, it becomes easier to identify outliers or anomalies. These anomalies could indicate errors, fraud, or emergent phenomena, particularly relevant in areas like cybersecurity, where detecting unusual patterns can help preempt security breaches. We will see more on this in Section 13.
Clustering also acts as a preprocessing step for other analytical procedures. By organizing data into clusters, subsequent algorithms can operate more efficiently and with reduced computational costs within each cluster. This method enhances performance in complex processes such as image and speech recognition, where initial clustering helps streamline the analysis.
In summary, clustering is not merely a methodological convenience but a robust tool for extracting and leveraging the complex, multidimensional structures in data, which in turn enhances decision-making across various domains.
12.1.3. Hard and Soft Clustering#
Clustering usually involves assigning each data point to exactly one cluster, making it a binary, either-or decision. This type of clustering is known as hard clustering. However, there are scenarios where allowing data points to belong to multiple clusters is advantageous, known as soft clustering. An example of soft clustering is shown in {numref}fig_clustering_hard_soft. In this introductory text, unless specified otherwise, we will primarily discuss hard clustering, where each element belongs to one, and only one, cluster.
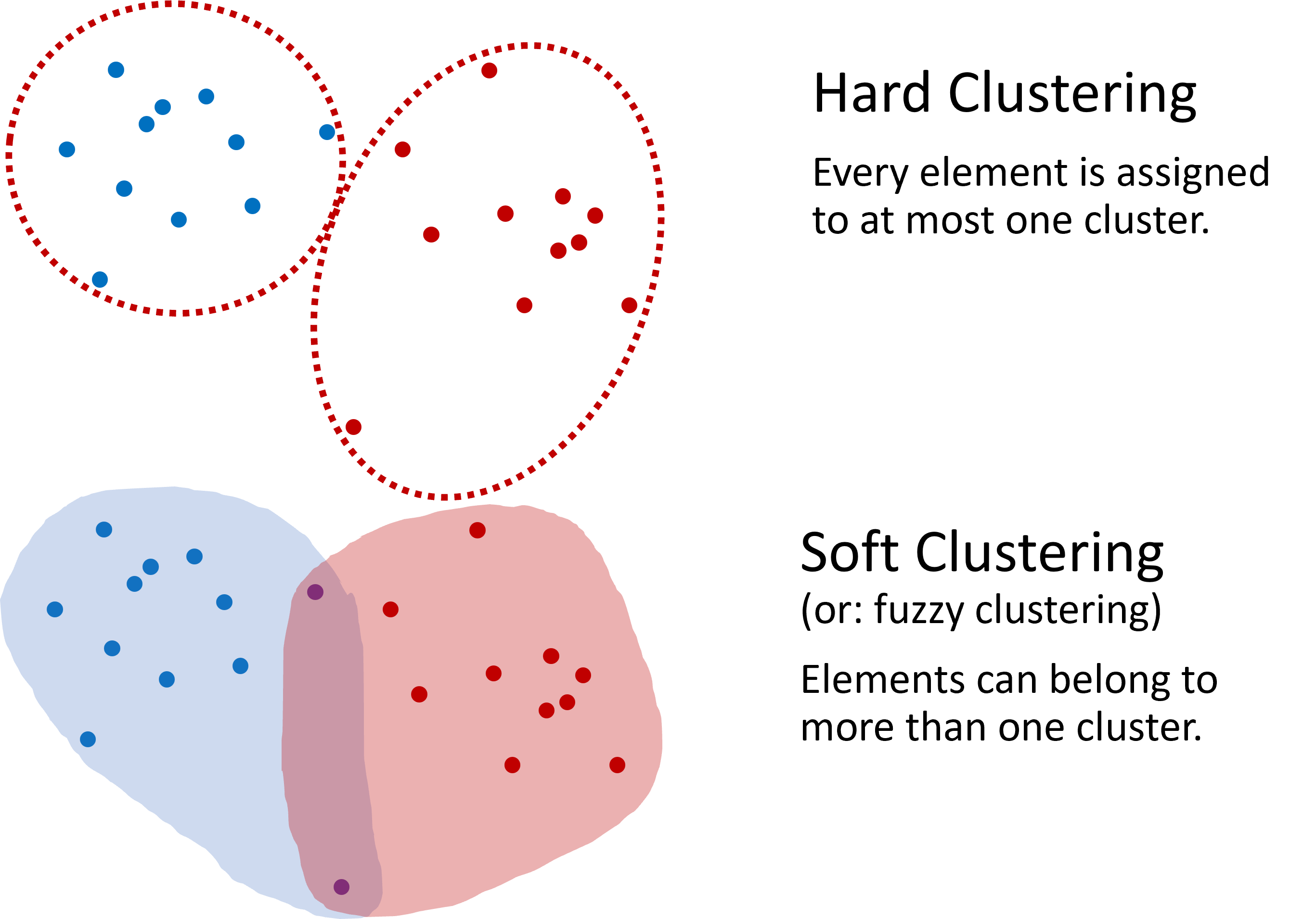
Fig. 12.2 Two distinct approaches are defined in clustering: hard clustering, where an element is exclusively part of one cluster, and soft clustering, which allows elements to overlap among multiple clusters. This book generally focuses on hard clustering unless otherwise noted.#
12.1.4. Mini-exercise#
Team up with your neighbor (if in a class), or try on your own:
Examine at the data displayed in Fig. 12.1. How would you design an algorithm to automatically assign each data point to a cluster it belongs to? Consider the following as you brainstorm:
How can you determine the closeness of points to suggest they belong to the same cluster?
What rules or criteria would you set for forming a cluster?
Make notes of your ideas and try to sketch out a simple algorithm or set of rules that could perform this clustering.
What did you come up with?
When I pose this question to students, I usually receive many different answers, many of which are viable approaches for the example shown. Common strategies include:
Distance-based clustering: Developing a rule based on the distance between points, where points are clustered together if they are within a certain distance from one another. This might involve calculating distances from every point to every other point or from points to a central location.
Geometric clustering: Some students suggest fitting lines, borders, or shapes among the scatter points to form boundaries between clusters.
Density-based clustering: Others propose methods that identify dense regions of points as individual clusters, possibly ignoring or separately categorizing outliers.
These diverse approaches highlight why numerous clustering algorithms have been developed, each with its own strengths and suitable applications. This exercise should help you appreciate the complexity of designing an algorithm that robustly and effectively identifies clusters in varied datasets
In the following, we will introduce and apply some very common clustering algorithms.
12.2. KMeans Clustering#
The K-means algorithm is a popular and intuitive method used for clustering and can be likened to the task of organizing similar items into buckets. To intuitively understand how it works, let’s imagine we are sorting fruit based on sweetness and size. Each fruit will be a data point with sweetness and size as its two features.
Here’s the step-by-step process:
Initialization: First, choose the number of buckets (clusters), say three for this fruit example. Begin by randomly selecting three fruits to act as the initial ‘centroids’ or representatives of these clusters.
Assignment: Assign each piece of fruit to the centroid it most closely resembles in terms of sweetness and size. The measurement of closeness could here be done based on the Euclidean distance between the features (sweetness and size).
Update Centroids: Once all fruits are assigned, recalculate each group’s centroid by finding the average sweetness and size of the fruits in that group. These averages become the new centroids.
Repeat Assignment and Update: Steps 2 and 3 are repeated. Fruits may switch buckets if they’re closer to a different centroid after the update. New centroids are calculated after the reassignments.
Convergence: This process of assignment and updating continues until things settle down – that is, the fruits no longer switch buckets (clusters), and the centroids no longer change. This is called convergence.
Result: At the end, we have our fruits sorted into buckets where each fruit is surrounded by others with similar sweetness and size. Each bucket represents a cluster.
In a more technical context, the ‘sweetness’ and ‘size’ are analogs for the features of the dataset, and the ‘average’ fruit represents the mean of the cluster’s points in feature space.
This iterative approach consists fundamentally of two steps: assigning data points to the nearest centroid and recalculating centroids. Despite its straightforward nature, KMeans has some limitations that need consideration.
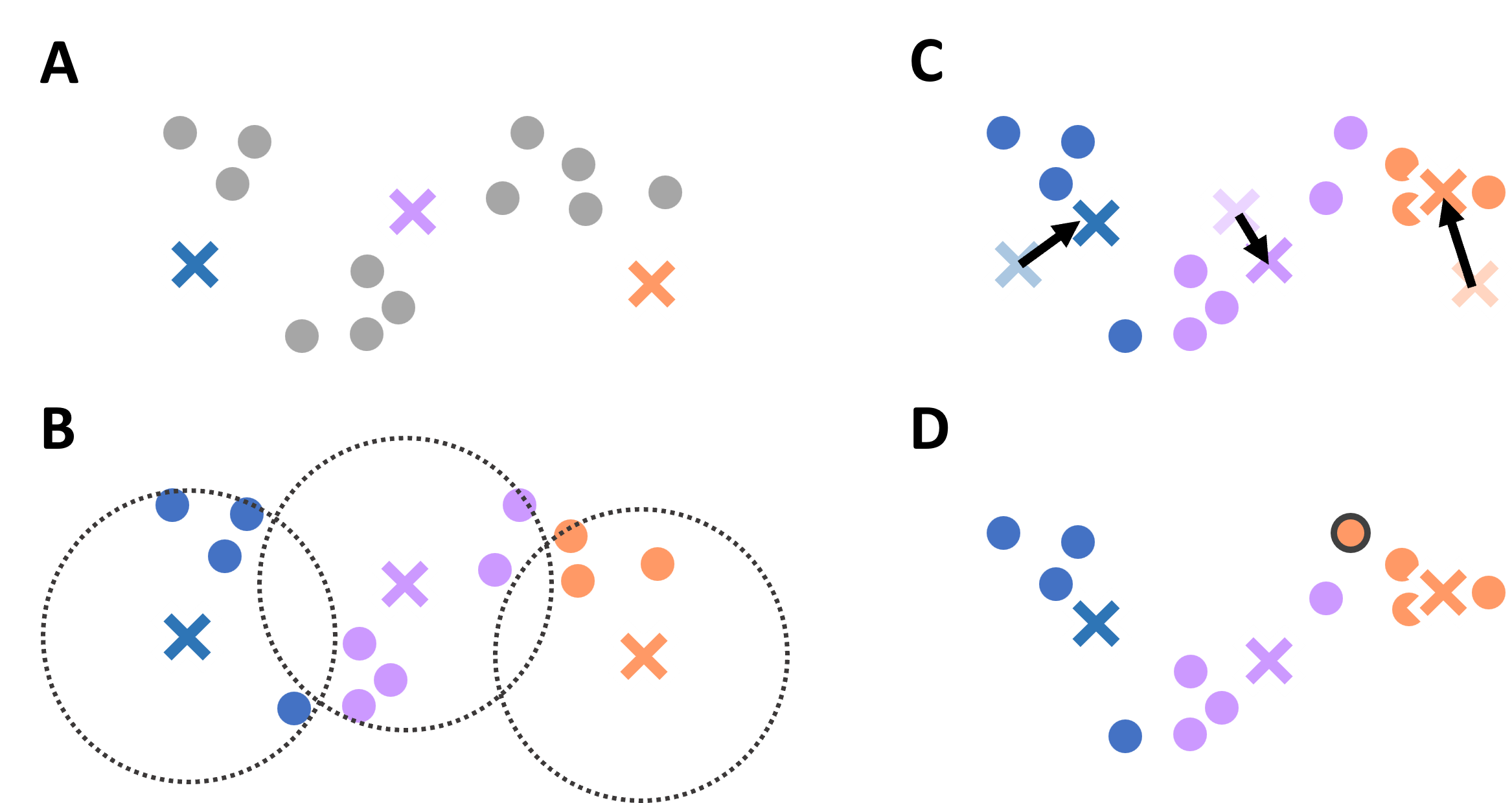
Fig. 12.3 Illustrative diagram of the K-means clustering process, showcasing the initialization of centroids, assignment of points to the nearest centroids, updating of centroids based on the assigned points, and the iterative process until convergence.#
In the following sections, we will make use of the Scikit-Learn implementations of several different clustering algorithms. The workflow will therefore look very similar in all cases, with the most notable difference the various main parameters that each of those algorithms requires. More information on the code implementations can be found on the Scikit-Learn documentation.
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=3, random_state=0).fit(data)
We visualize the resulting clustering. Each cluster is shown with a different color.
fig, ax = plt.subplots(figsize=(7, 7), dpi=300)
ax.scatter(data[:,0], data[:,1], c=kmeans.labels_)
plt.axis("off")
plt.show()

12.2.1. Very often, clusters are not that easily distinguishable!#
In the following code blocks we create a new synthetic dataset with five clusters, and visualize it. This is already one step more “realistic” in the sense that most commonly we do not deal with ideally distinctive clusters an shown in the examples above. Very often is is not so clear where a cluster begins and where one ends, nor how many clusters we actually have.
clusters = [(61, 1, 1.5, 2.5, -0.7),
(37, 0.8, 0.5, 1.1, -1.2),
(49, 1.1, 1.2, -2.6, 2.3),
(44, 0.45, 0.4, 0.5, 2.3),
(70, 0.9, 0.3, -2.5, -1.7)]
np.random.seed(1)
data = np.zeros((0, 2))
for (n_points, x_scale, y_scale, x_offset, y_offset) in clusters:
xpts = np.random.randn(n_points) * x_scale + x_offset
ypts = np.random.randn(n_points) * y_scale + y_offset
data = np.vstack((data, np.vstack((xpts, ypts)).T))
data.shape
(261, 2)
fig, ax = plt.subplots(figsize=(7, 7), dpi=300)
ax.scatter(data[:,0], data[:,1], color="teal")
# plt.savefig("example_clustering_01.png", dpi=300, bbox_inches="tight")
<matplotlib.collections.PathCollection at 0x7fedbe10ae00>
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=5, random_state=0).fit(data)
kmeans.labels_
array([1, 1, 1, 1, 1, 3, 1, 3, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 4, 1, 1,
1, 4, 1, 1, 1, 4, 1, 1, 1, 1, 4, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 4, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 4, 0, 0, 0, 0,
0, 3, 0, 0, 4, 0, 0, 0, 0, 0, 3, 0, 3, 0, 3, 0, 0, 3, 0, 0, 0, 0,
0, 0, 0, 3, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 2, 2, 4, 2, 2, 2, 2,
2, 2, 4, 2, 4, 2, 4, 2, 4, 2, 4, 2, 2, 4, 4, 2, 2, 2, 2, 4, 4, 2,
4, 4, 2, 2, 2, 2, 4, 4, 2, 2, 4, 2, 2, 4, 2, 2, 4, 2, 2, 4, 4, 4,
2, 4, 2, 4, 4, 4, 4, 4, 2, 2, 4, 2, 4, 2, 4, 2, 4, 2, 4],
dtype=int32)
kmeans.cluster_centers_
array([[-2.99127157, 2.52658441],
[ 2.17250303, -0.81179254],
[-3.14602055, -1.70083386],
[ 0.42175481, 2.27101038],
[-1.32008432, -1.60712121]])
fig, ax = plt.subplots(figsize=(7, 7), dpi=300)
ax.scatter(data[:,0], data[:,1], c=kmeans.labels_)
ax.scatter(kmeans.cluster_centers_[:, 0],
kmeans.cluster_centers_[:, 1], marker="x", color="crimson")
ax.set_title("K-Means clustering with k=5")
plt.show()
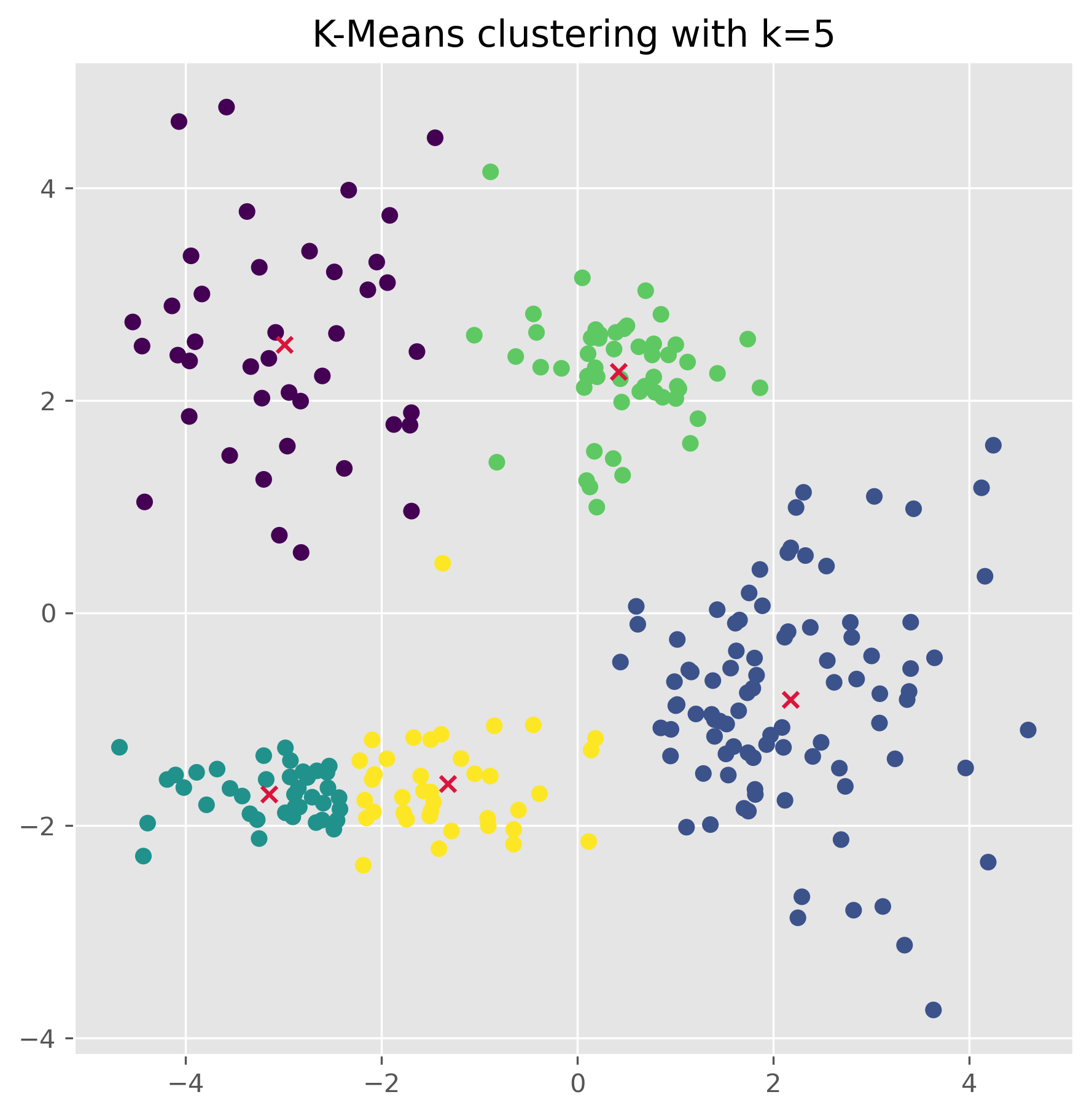
Once the clusters have been found (using the .fit() method as done above), we can also use a k-means model to make predctions on unknown datapoints.
kmeans.predict([[-2, 0], [4, 3]])
array([4, 3], dtype=int32)
We can also check the found cluster center points:
kmeans.cluster_centers_
array([[-2.99127157, 2.52658441],
[ 2.17250303, -0.81179254],
[-3.14602055, -1.70083386],
[ 0.42175481, 2.27101038],
[-1.32008432, -1.60712121]])
12.2.2. Advantages of KMeans:#
Simplicity: The algorithm is easy to understand and implement.
Efficiency: It is computationally efficient, making it suitable for large datasets.
Effectiveness: Performs well with clusters that are relatively isotropic and similar in size.
12.2.3. Disadvantages of KMeans:#
Fixed Number of Clusters: Requires specifying the number of clusters beforehand, which is not always known in advance and can be difficult to estimate.
Cluster Assumptions: Assumes that clusters are spherical and of similar size, which may not hold true for all datasets.
Sensitivity to Initial Conditions: The initial placement of centroids can affect the final outcome, and KMeans can sometimes converge to a local minimum rather than the global best solution.
Outlier Sensitivity: Outliers can skew the centroids, making KMeans less robust to anomalous data points.
12.3. DBSCAN (Density-Based Spatial Clustering of Applications with Noise)#
DBSCAN stands for Density-Based Spatial Clustering of Applications with Noise. It’s like an adventurous hike where we group together hikers based on how closely they walk together and how often they stop to rest. To explain DBSCAN in an accessible way, let’s consider our hikers as data points in a park (our dataset).
How DBSCAN works:
Starting Point (Core Points): First, select a hiker and check how many others are within a preset distance (
epsilon). If a sufficient number (defined bymin_samples) are within this range, this hiker becomes a core of a potential cluster.Forming Groups (Cluster Expansion): From our core hiker, we extend the group by asking each new hiker in the epsilon area to invite other hikers within their own epsilon area. If these hikers also have enough companions within their reach, the group grows – this is how DBSCAN expands clusters.
Connecting Groups (Density Reachability): Sometimes, a hiker might not have enough people within their epsilon distance to form their own core group but is close enough to be part of the existing group. These hikers act as bridges and help in joining different core groups, forming a larger cluster.
Identifying Lone Hikers (Noise Detection): Some hikers prefer solitude and are too far from others to join any group. These are labeled as ‘noise’—similar to outliers in data.
Adapting to Terrain (Handling Different Densities): Just as groups of hikers might spread out in open fields and bunch up in narrow trails, DBSCAN tries to adapt to areas of different point densities. This can be tricky because the same ‘epsilon’ and
min_samplesmight not work for both sparse and dense areas, which is a challenge for DBSCAN.Exploring the Entire Park (Full Dataset): The process continues until all hikers are either grouped or labeled as noise. Unlike K-means, we don’t need to know how many groups (clusters) we want to form in advance – the hikers (data points) naturally form groups based on their proximity and the number of companions they have.
DBSCAN is particularly effective for complex datasets with non-linear cluster shapes and varying densities. However, the choice of epsilon and min_samples is crucial, as it significantly impacts the clustering results.
Using Scikit-Learn, we can use DBSCAN as follows:
from sklearn.cluster import DBSCAN
dbscan = DBSCAN(eps=0.5, min_samples=2).fit(data)
dbscan.labels_
array([ 0, 1, 1, 1, 1, 2, 0, 3, 4, 5, -1, 1, 1, 1, -1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 6, 1, 1, 1, 1,
1, 1, 1, 1, -1, 1, 1, 1, 1, -1, 1, 1, -1, -1, 1, 4, 1,
1, 1, 1, 5, 1, 4, 6, 1, 1, 1, 1, 1, 7, 1, 1, 1, 8,
1, 1, 1, -1, 1, 1, 1, 1, 8, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 7, 1, 1, 1, 1, 1, 1, 1, 9, 9, 10, -1,
11, 10, 12, 7, -1, 13, -1, -1, 13, 3, 12, 13, -1, -1, -1, -1, 9,
12, 3, 12, -1, 9, -1, 9, 13, 2, 12, 11, -1, 12, 9, -1, 10, 3,
9, 13, 13, 12, 13, -1, 12, 12, 12, 13, 12, 2, 2, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 2, 3, 3, 3, 3, 2, 3, 3, 3, 3, 3, 3, 3, 3, -1, 3,
3, 3, 3, 3, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7,
7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7,
7, 7, -1, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7,
7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7,
7, 7, 7, 7, 7, 7])
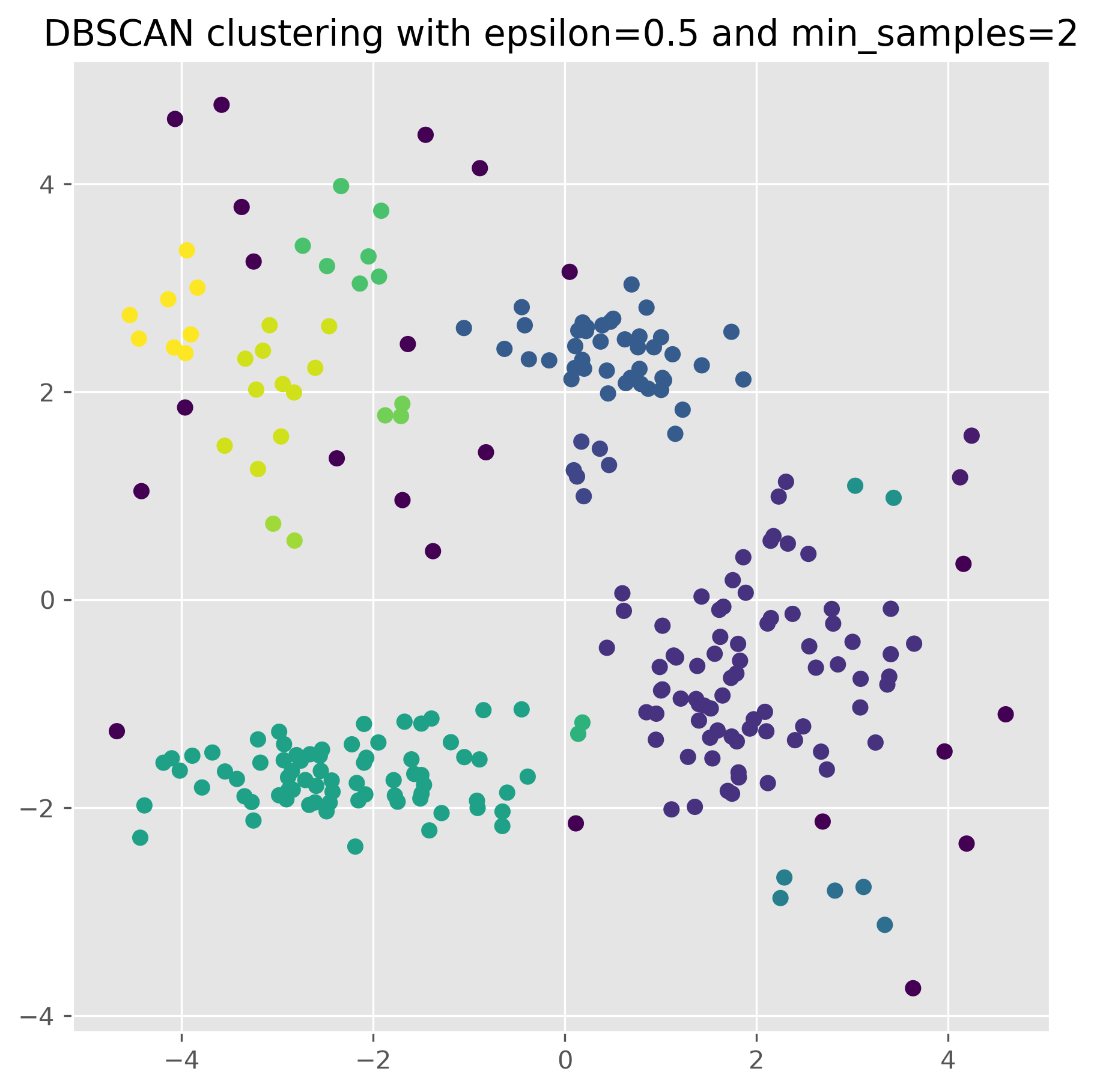
fig, ax = plt.subplots(figsize=(7, 7), dpi=300)
ax.scatter(data[:,0], data[:,1], c=dbscan.labels_)
ax.set_title("DBSCAN clustering with epsilon=0.5 and min_samples=2")
plt.show()
12.3.1. Parameter variation#
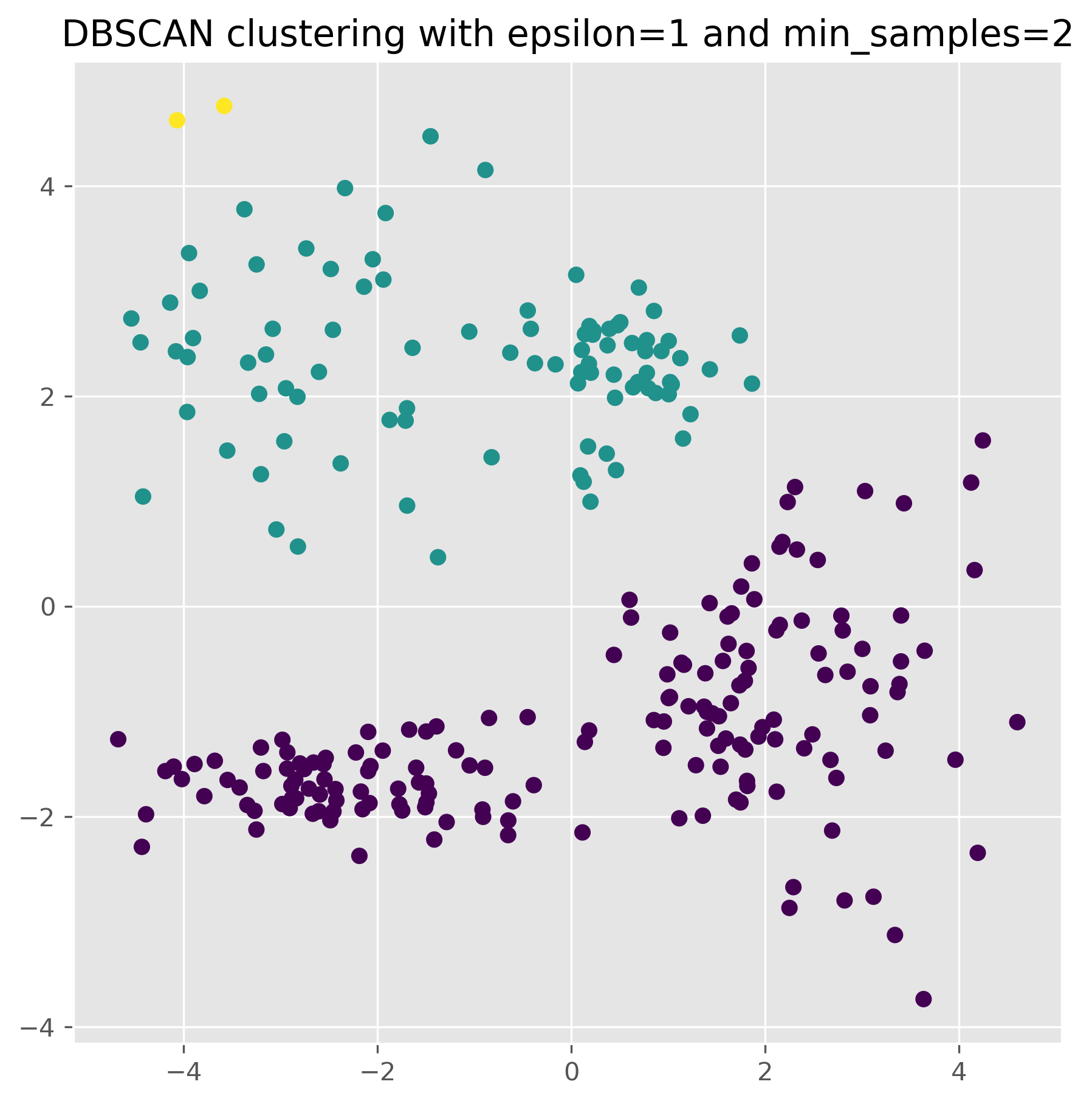
For DBSCAN to work, we usually have to find a good pair of parameters for epsilon and min_samples. In particular the epsilon value has a huge impact on the results.
dbscan = DBSCAN(eps=1, min_samples=2).fit(data)
fig, ax = plt.subplots(figsize=(7, 7), dpi=300)
ax.scatter(data[:,0], data[:,1], c=dbscan.labels_)
ax.set_title("DBSCAN clustering with epsilon=1 and min_samples=2")
plt.show()
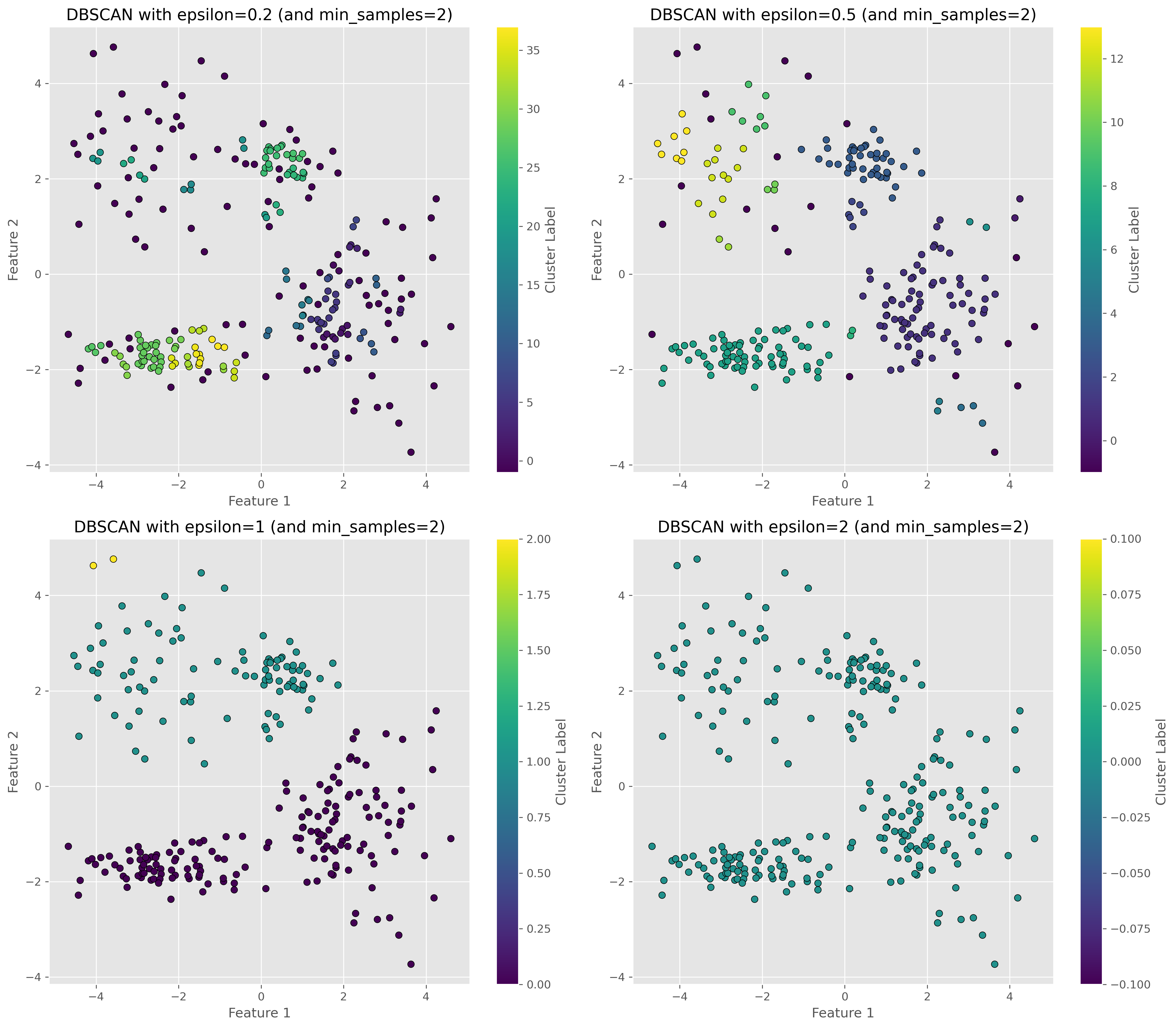
Show code cell source
# Create a subplot grid
fig, axes = plt.subplots(2, 2, figsize=(15, 13), dpi=300)
# Enumerate over desired distance thresholds
epsilons = [0.2, 0.5, 1, 2]
for i, eps in enumerate(epsilons):
dbscan = DBSCAN(eps=eps, min_samples=2).fit(data)
# Plot the results
ax = axes[i // 2, i % 2]
scatter = ax.scatter(data[:, 0], data[:, 1], c=dbscan.labels_, cmap='viridis', edgecolor='k')
# Enhancements for clarity
ax.set_title(f"DBSCAN with epsilon={eps} (and min_samples=2)")
ax.set_xlabel('Feature 1')
ax.set_ylabel('Feature 2')
fig.colorbar(scatter, ax=ax, label='Cluster Label')
plt.tight_layout()
plt.show()
12.3.2. Advantages of DBSCAN:#
Adaptive Clustering: Automatically determines the number of clusters based on data density, eliminating the need to predefine this number.
Handles Arbitrary Shapes: Efficiently identifies clusters of various shapes, adapting to the actual distribution of data points.
Outlier Detection: Effectively differentiates between core clusters and noise, enhancing its robustness against outliers.
12.3.3. Disadvantages of DBSCAN:#
Sensitivity to Parameters: Highly dependent on the settings for
epsilonandmin_samples, which can significantly impact clustering outcomes.Struggles with Varying Densities: May fail to accurately define clusters when they vary widely in density, treating sparse clusters as noise.
Computational Complexity: While generally efficient, its performance may degrade with very large datasets or those with high dimensionality due to the complexity of density calculations.
12.4. Gaussian mixture models#
Gaussian Mixture Models (GMM) can be thought of as a sophisticated extension of the K-means clustering technique, with added flexibility. If we were to visualize data clustering as a process of sorting different types of coins based on their size and weight, K-means would sort them into predefined buckets, while GMM would be like having scales and calipers that tell us not just which bucket a coin most likely belongs to, but also provide a measure of our certainty about it.
How GMM works:
Assumptions: GMM starts with the assumption that our data points are generated from a mixture of several Gaussian distributions. Each Gaussian, also known as a normal distribution, represents a cluster. It’s like assuming that coins come from different countries, each with its unique size and weight characteristics.
Expectation-Maximization (EM) Steps:
Expectation (E-step): Here, the algorithm assesses each data point and estimates the probabilities of it belonging to each of the Gaussian distributions (clusters). In our coin analogy, this is like guessing the origin of a coin based on its size and weight, but instead of being certain, we assign probabilities to the likelihood of it coming from each country.
Maximization (M-step): Based on these probabilities, GMM updates the parameters of the Gaussian distributions—namely, the means (which are like the centroid in K-means), the variances (which tell us how spread out each cluster is), and the mixture weights (which tell us how large or small each cluster is compared to others). This is akin to adjusting our scale and calipers based on all the coins we’ve measured to better fit the actual data.
Iterative Process: These two steps are repeated iteratively, with each pass refining the parameters and improving the model’s accuracy in representing the underlying clusters.
Soft Clustering: Unlike K-means, which assigns each point to a single cluster, GMM provides a probability distribution over the clusters for each point, indicating its degree of membership in every cluster. This soft assignment is particularly useful when we’re not sure about the boundaries of clusters, much like a coin that’s in-between typical sizes and weights for known designs.
Final Model: After several iterations, when the changes in the parameters become negligible, the algorithm has hopefully converged to the best fit for our data, and we have a final model that tells us not only where the clusters are, but also how certain we can be about each data point’s membership.
from sklearn.mixture import GaussianMixture
gm = GaussianMixture(n_components=5, random_state=0).fit(data)
gm.means_
array([[-2.80121071, 2.49623595],
[ 2.08237568, -0.79412545],
[-2.96321278, -1.69907782],
[ 0.49887671, 2.26838731],
[-1.43864991, -1.67923165]])
labels = gm.predict(data)
fig, ax = plt.subplots(figsize=(7, 7), dpi=300)
ax.scatter(data[:,0], data[:,1], c=labels)
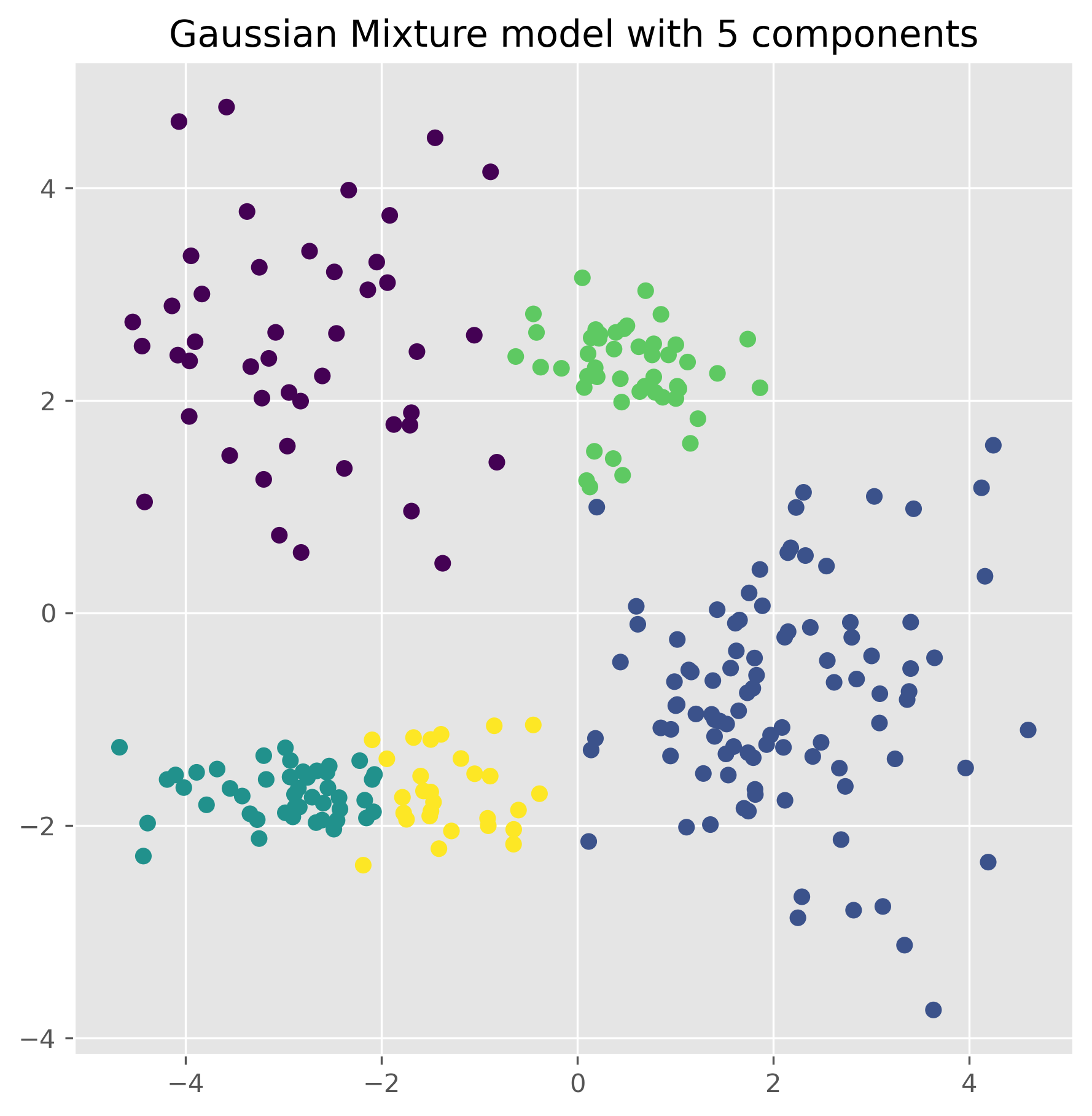
ax.set_title("Gaussian Mixture model with 5 components")
plt.show()
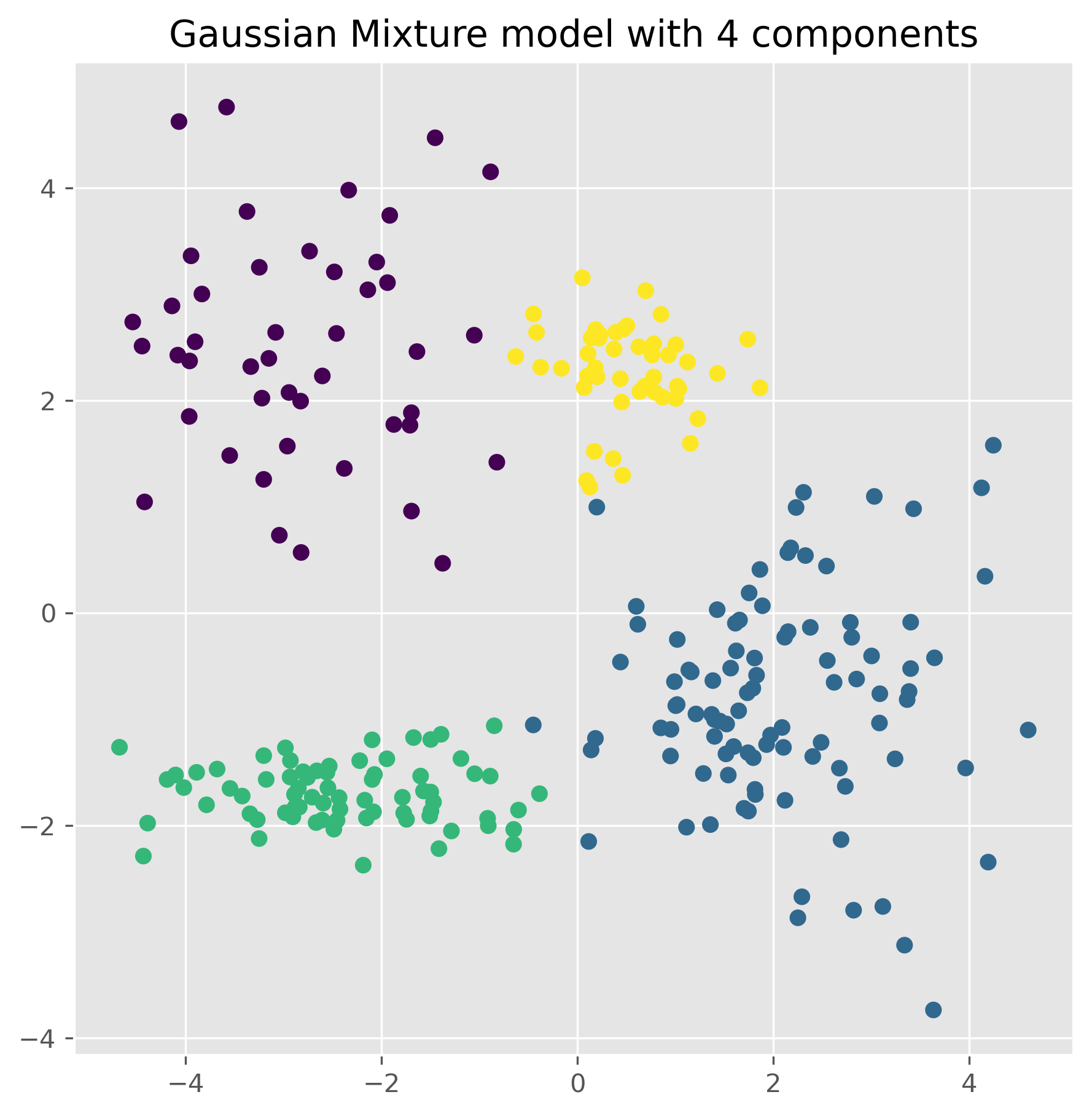
gm = GaussianMixture(n_components=4, random_state=0).fit(data)
fig, ax = plt.subplots(figsize=(7, 7), dpi=300)
ax.scatter(data[:,0], data[:,1], c=gm.predict(data))
ax.set_title("Gaussian Mixture model with 4 components")
plt.show()
Show code cell source
from matplotlib.patches import Ellipse
from scipy import linalg
import itertools
# Color iterator for different clusters
color_iter = itertools.cycle(['teal', 'cornflowerblue', 'gold', 'crimson', 'c'])
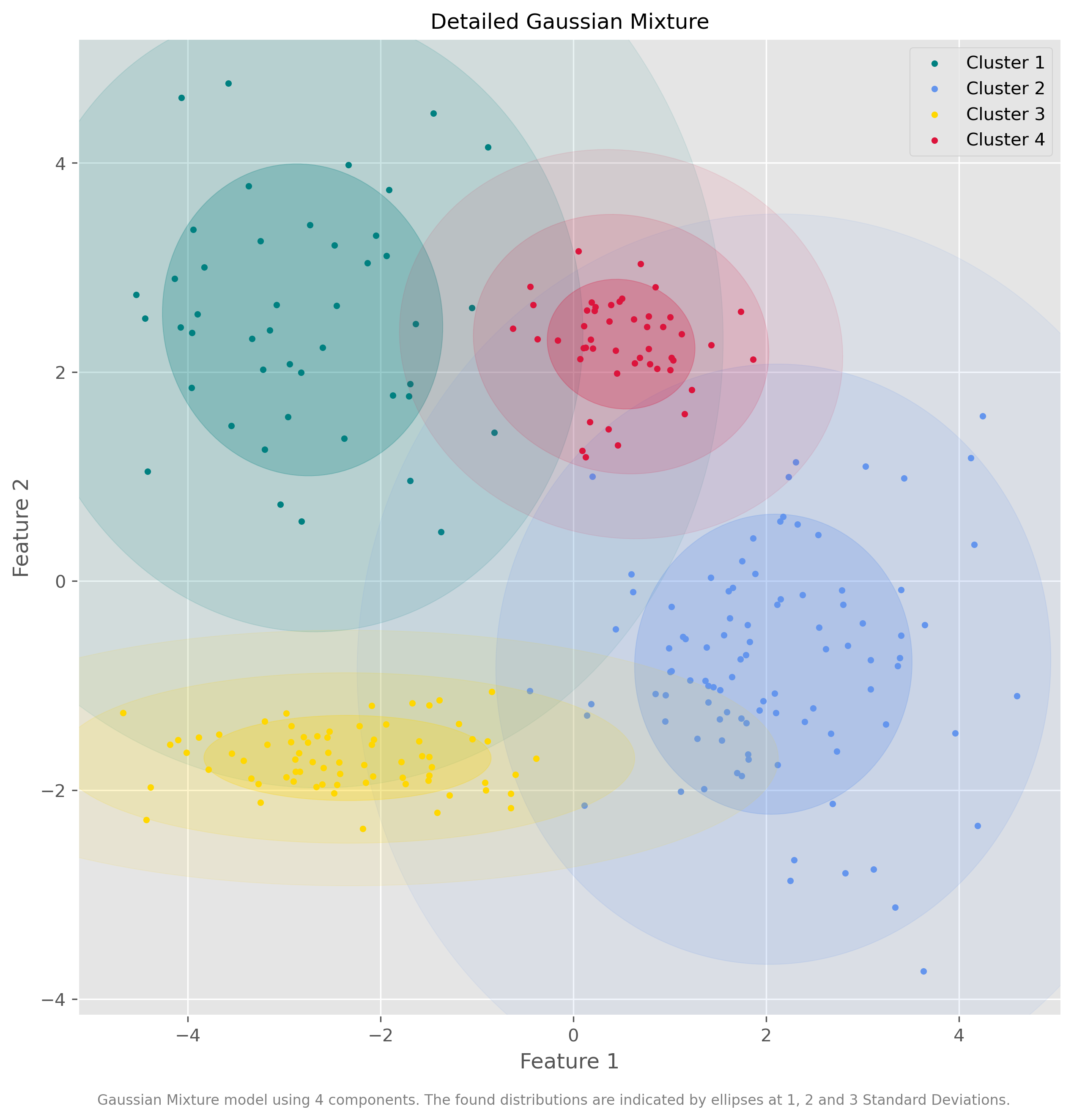
def plot_gmm(X, Y_, means, covariances, title):
"""Plot the Gaussian Mixture Model with multiple ellipses to show the distribution density."""
fig, ax = plt.subplots(figsize=(10, 10), dpi=300)
for i, (mean, covar, color) in enumerate(zip(means, covariances, color_iter)):
if not np.any(Y_ == i):
continue
ax.scatter(X[Y_ == i, 0], X[Y_ == i, 1], s=10, color=color, label=f'Cluster {i+1}')
# Calculate the eigenvalues and eigenvectors for the covariance matrix
v, w = linalg.eigh(covar)
v = 2. * np.sqrt(2.) * np.sqrt(v)
# Calculate the angle of the ellipse
u = w[0] / linalg.norm(w[0])
angle = np.arctan2(u[1], u[0])
angle = 180. * angle / np.pi # Convert to degrees
# Plot ellipses at 1 std, 2 std, and 3 std
for std_dev in range(1, 4):
ell = Ellipse(mean, std_dev * v[0], std_dev * v[1], angle=180. + angle, color=color)
ell.set_clip_box(ax.bbox)
ell.set_alpha(0.25 / std_dev) # Decrease alpha as std_dev increases
ax.add_artist(ell)
ax.set_title(title, fontsize=12)
ax.set_xlabel("Feature 1")
ax.set_ylabel("Feature 2")
plt.legend()
fig.text(0.5, 0.04,
"Gaussian Mixture model using 4 components. The found distributions are indicated by ellipses at 1, 2 and 3 Standard Deviations.",
ha="center", fontsize=8, color="gray")
plt.show()
# Run plotting function
plot_gmm(data, gm.predict(data), gm.means_, gm.covariances_, "Detailed Gaussian Mixture")
12.4.1. Advantages of GMM:#
Flexibility: GMM can accommodate clusters of various shapes, sizes, and orientations, making it more versatile than simpler methods like K-means.
Soft Clustering: It provides a probabilistic model of cluster membership, offering a nuanced view of each data point’s placement.
12.4.2. Disadvantages of GMM:#
Number of Clusters: Like K-means, GMM requires the user to predetermine the number of clusters, which can be challenging without prior knowledge of the dataset.
Computational Intensity: It is generally more computationally demanding than K-means due to the complexity of its calculations.
Data Requirements: GMM necessitates a sufficiently large data set to effectively estimate the parameters of Gaussian distributions.
12.5. Hierarchical clustering (Ward)#
Hierarchical clustering, especially the Ward method, can be visualized as creating a family tree of data points, showing the relationships between clusters from the ground up. Imagine organizing a large collection of books on shelves to understand this concept better.
12.5.1. How Hierarchical Clustering Works:#
Initialization (Every Book as a Cluster): Initially, each book is treated as its own cluster. This bottom-up approach starts with every item in its own group.
Agglomeration (Creating Shelves): Books are grouped based on similarity, typically measured by the distance between them. The Ward method minimizes within-cluster variance, aiming to place books of similar sizes or genres together for a neater arrangement.
Building the Hierarchy (Forming Sections): As books are grouped, we begin to see not just individual books or pairs, but larger groups and subgroups, each akin to a branch on a family tree of book categories.
Creating the Dendrogram (Forming a Library): The process continues until all books are grouped in a way that illustrates their relationships, from individual books to entire genre sections. This is represented by a dendrogram—a tree-like diagram that records the sequences of merges.
Determining the Number of Clusters (Deciding on Genres): A key advantage of hierarchical clustering is that it does not require a predetermined number of clusters. Once the dendrogram is complete, we can ‘cut’ it at a level that makes sense, choosing either broad genres or specific sub-genres based on our requirements.
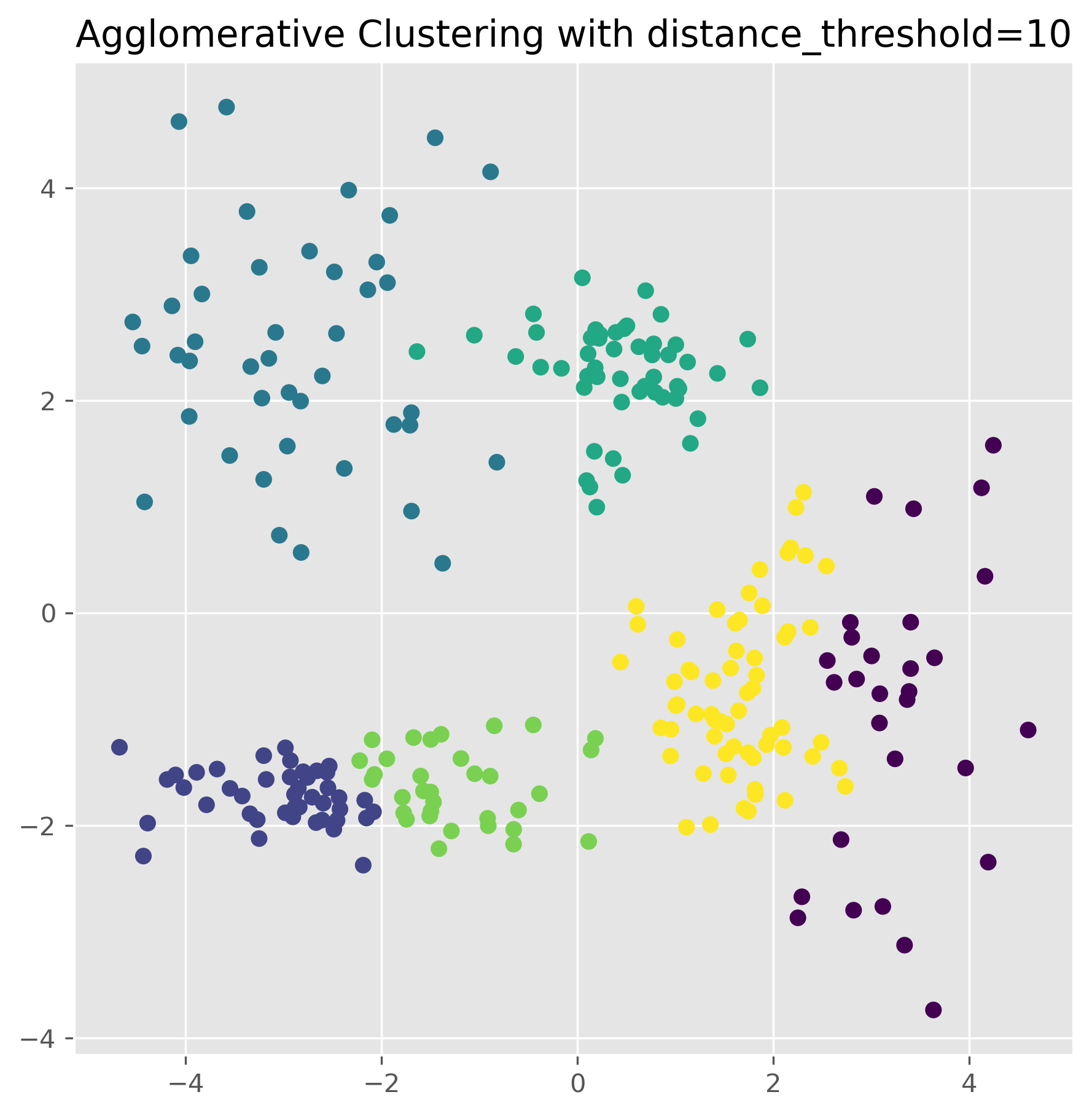
from sklearn.cluster import AgglomerativeClustering
ward = AgglomerativeClustering(linkage="ward",
n_clusters=None,
distance_threshold=10.0).fit(data)
fig, ax = plt.subplots(figsize=(7, 7), dpi=300)
ax.scatter(data[:,0], data[:,1], c=ward.labels_)
ax.set_title("Agglomerative Clustering with distance_threshold=10")
plt.show()
12.5.1.1. Parameter variation#
Just as the other clustering techniques, hierarchical clustering also requires defining key parameters. In the present case the distance_threshold is one of the most important parameters to explore and choose. As the following figure illustrates, this parameters has a drastic impact on the number of clusters found.
Show code cell source
from sklearn.cluster import AgglomerativeClustering
# Create a subplot grid
fig, axes = plt.subplots(2, 2, figsize=(15, 13), dpi=300)
# Enumerate over desired distance thresholds
distance_thresholds = [20, 10, 5, 2]
for i, distance_threshold in enumerate(distance_thresholds):
# Fit the model
ward = AgglomerativeClustering(linkage="ward", n_clusters=None, distance_threshold=distance_threshold)
ward.fit(data)
# Plot the results
ax = axes[i // 2, i % 2]
scatter = ax.scatter(data[:, 0], data[:, 1], c=ward.labels_, cmap='viridis', edgecolor='k')
# Enhancements for clarity
ax.set_title(f"Agglomerative Clustering with distance_threshold={distance_threshold}")
ax.set_xlabel('Feature 1')
ax.set_ylabel('Feature 2')
fig.colorbar(scatter, ax=ax, label='Cluster Label')
plt.tight_layout()
plt.show()
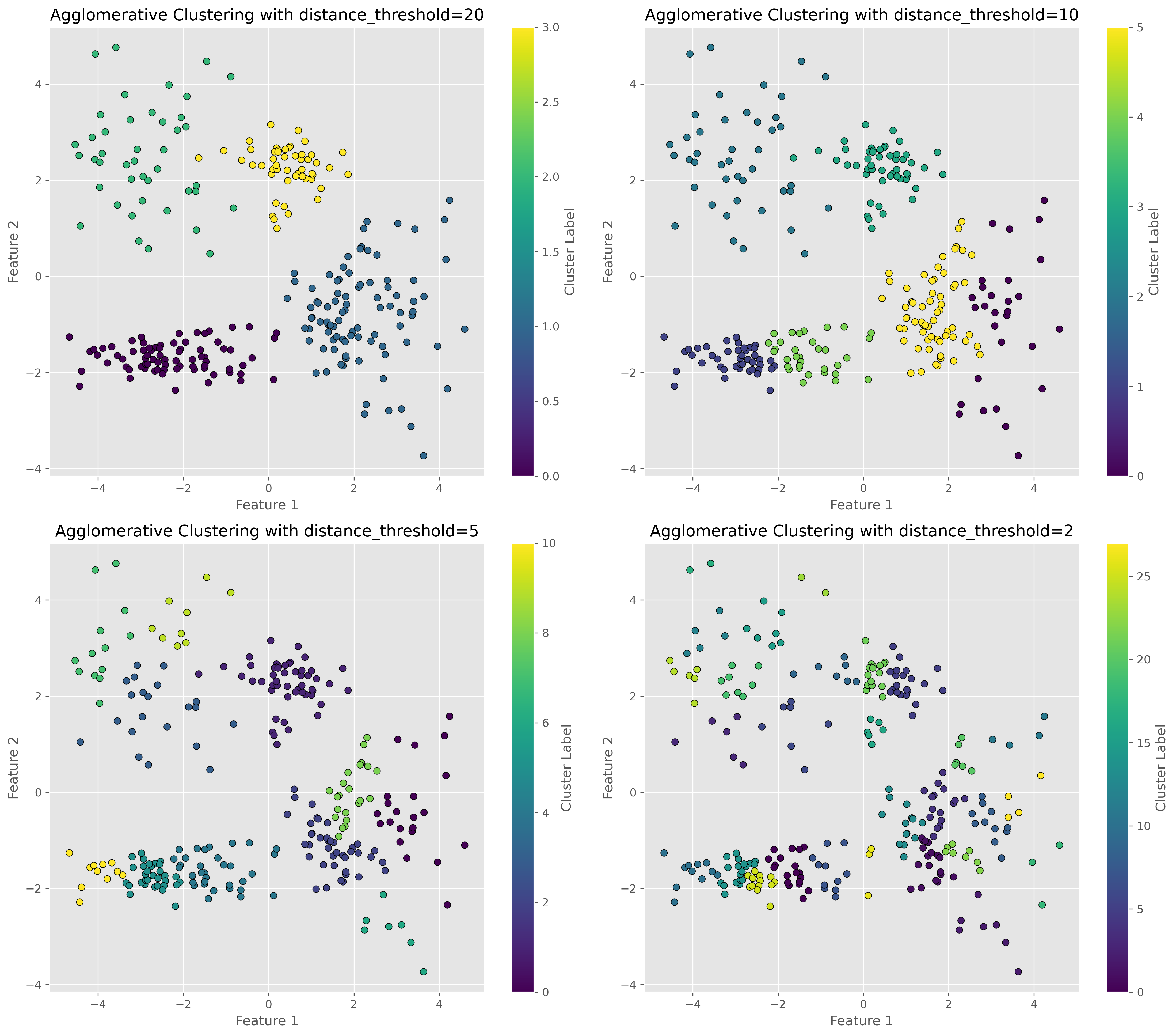
But, what is this distance threshold?
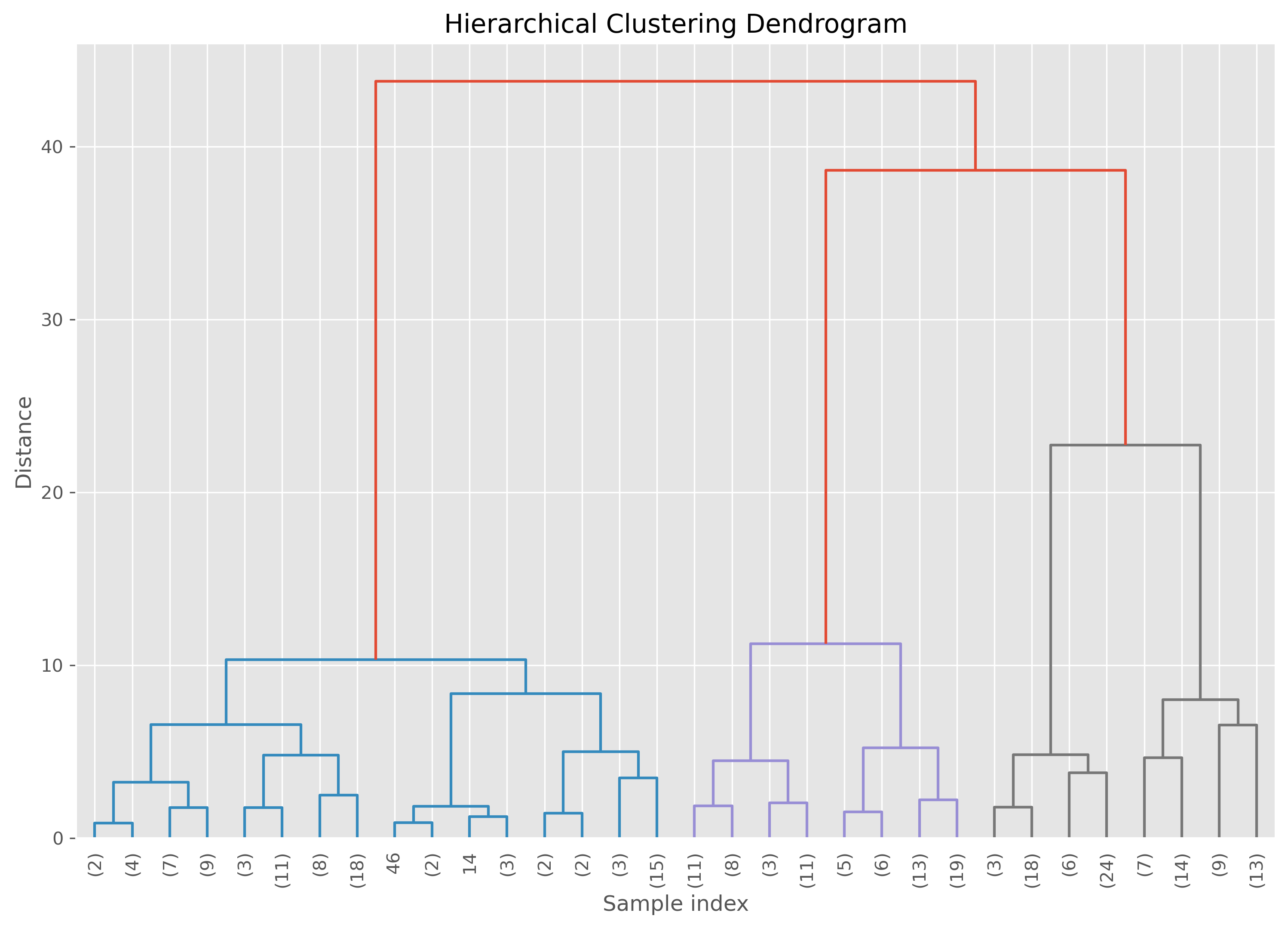
This threshold here defines where we cut othe dendrogram. The lower the distance the closer this cut is to the individual datapoints and thereby the more clusters we will get. See in the following plot how the dendrogram for our specific case looks like. To increase clarity, we here truncate the dendrogram to not go fully until the individuall datapoints.
Show code cell source
from scipy.cluster.hierarchy import dendrogram
from sklearn.datasets import load_iris
from sklearn.cluster import AgglomerativeClustering
def plot_dendrogram(model, **kwargs):
"""
Plots a dendrogram based on the linkage matrix derived from an AgglomerativeClustering model.
Parameters:
- model : AgglomerativeClustering
The hierarchical clustering model fitted from sklearn.
- **kwargs : dict
Additional keyword arguments for the scipy dendrogram function.
"""
# Number of samples
n_samples = len(model.labels_)
# Create the counts of samples under each node (non-leaf nodes)
counts = np.zeros(model.children_.shape[0])
for i, merge in enumerate(model.children_):
current_count = 0
for child_idx in merge:
# Check if the index is a leaf node or a merged node
if child_idx < n_samples:
current_count += 1 # It's a leaf node
else:
# It's a merged node, add the count from the counts array
current_count += counts[child_idx - n_samples]
counts[i] = current_count
# Create the linkage matrix needed for the dendrogram
linkage_matrix = np.column_stack([model.children_, model.distances_, counts]).astype(float)
# Plot the dendrogram using the generated linkage matrix
dendrogram(linkage_matrix, **kwargs)
# Plot the dendrogram
plt.figure(figsize=(12, 8), dpi=300) # Set the figure size for better visibility
plot_dendrogram(ward,
leaf_rotation=90,
leaf_font_size=10,
truncate_mode="level",
p=4)
plt.title('Hierarchical Clustering Dendrogram')
plt.xlabel('Sample index')
plt.ylabel('Distance')
plt.show()
12.5.2. Advantages of Hierarchical Clustering:#
Flexibility in Number of Clusters: Unlike many clustering techniques, hierarchical clustering doesn’t compel us to decide on the number of clusters at the start. This decision can be made by analyzing the dendrogram at different cuts.
Visual Insights: It provides a visual representation of the data hierarchy, which can be incredibly insightful for understanding the relationships between clusters.
12.5.3. Disadvantages of Hierarchical Clustering:#
Computational Intensity: This method can be computationally demanding, particularly with large datasets. It’s akin to manually organizing an extensive library.
Irreversibility of Merges: Once made, early decisions in the agglomerative process cannot be undone without restarting, which can sometimes lead to suboptimal clustering.
Decision on Cluster Cut: Despite not needing to predefine the number of clusters, a criterion is still required to decide where to cut the dendrogram, which effectively determines the final number of clusters.
12.6. Clustering on Actual Data#
So far, the different clustering algorithms have been introduced and applied to simple toy data to facilitate understanding of their mechanics and key characteristics. However, for these clustering algorithms to be effective on more realistic and usually more complex datasets, several additional considerations must be addressed. This includes preprocessing steps, dealing with high dimensionality, and selecting meaningful features.
12.6.1. Data Preprocessing#
Standardization: Most clustering algorithms, including K-means and GMM, assume that features have the same scale for them to perform optimally. Standardization (or Z-score normalization) is crucial as it scales the data to have a mean of zero and a standard deviation of one. This ensures that each feature contributes equally to the distance calculations, which is vital for distance-based algorithms.
python
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
data_scaled = scaler.fit_transform(data)
Handling Missing Values: Real-world data often contains missing values, which can significantly affect the performance of clustering algorithms. Depending on the context, you might choose to impute missing values using the median or mode, or exclude data points or features with high rates of missingness.
Outlier Detection and Treatment: Outliers can skew the results of clustering algorithms, particularly those like K-means, which rely on mean values. Identifying and addressing outliers through methods such as trimming or capping can be necessary before applying clustering.
12.6.2. Feature Selection#
Dimensionality Reduction: High-dimensional spaces can be problematic for clustering due to the “curse of dimensionality,” which generally leads to overfitting and poor clustering performance. Techniques such as PCA (Principal Component Analysis) or t-SNE (t-Distributed Stochastic Neighbor Embedding) can reduce the number of dimensions while retaining the essential characteristics of the data.
We will look at dimensionality reduction in detail in the next section.
Feature Engineering: Creating new features that capture essential characteristics of the data can also enhance clustering outcomes. This might involve aggregating features, creating interaction terms, or incorporating domain-specific knowledge into feature design.
12.7. Comparison and Conclusion#
In this section, we have explored four different clustering algorithms: K-means, DBSCAN, Gaussian Mixture Model (GMM), and hierarchical clustering. Each method offers unique advantages and comes with its own set of limitations.
K-means is a simple and easy-to-understand algorithm that works well with isotropic clusters. Its limitations include the requirement to predefine the number of clusters, sensitivity to initial conditions, and a tendency to converge to a local minimum rather than the global optimum.
DBSCAN stands out for not requiring the number of clusters to be specified and for its ability to identify clusters of arbitrary shapes and robustness to noise. However, DBSCAN may struggle with clusters of varying densities, and the choice of hyperparameters (epsilon and min_samples) can significantly affect the results.
Gaussian Mixture Models (GMM) provide a probabilistic framework that assumes each cluster follows a Gaussian distribution, offering greater flexibility than K-means in terms of cluster covariance. While GMM can model clusters of different shapes, sizes, and orientations, it requires specification of the number of clusters and is more computationally intensive.
Hierarchical Clustering builds a hierarchy of clusters, either agglomerative (bottom-up) or divisive (top-down), with the Ward method being an example that minimizes the within-cluster variance. This method doesn’t require specifying the number of clusters, offering a visual dendrogram to aid in cluster selection, though it is computationally expensive for large datasets.
In conclusion, the choice of clustering algorithm depends on the data, the problem, and the desired characteristics of the clustering solution. It is often helpful to try multiple algorithms and compare their results to select the best method for a particular problem.
12.8. More on Clustering#
Not surprisingly, there is much more to learn and explore about clustering algorithms and their applications. For a start, it makes sense to have a look at some of the other clustering algorithms what can be found within Scikit-learn’s clustering module.
There is also plenty of books, tutorials, articles on various clustering techniques. Here just one more recent scientific review article on different clustering techniques:
“A review of clustering techniques and developments” by Amit Saxena and Mukesh Prasad and Akshansh Gupta and Neha Bharill and Om Prakash Patel and Aruna Tiwari and Meng Joo Er and Weiping Ding and Chin-Teng Lin, 2017, Neurocomputing, Vol.267, https://doi.org/10.1016/j.neucom.2017.06.053 [Saxena et al., 2017]